")
Um SO - sistema operativo (português europeu) ou sistema operacional (português brasileiro) ou os - operating system (inglês) é um programa ou um conjunto de programas cuja função é gerenciar os recursos do sistema (definir qual programa recebe atenção do processador, gerenciar memória, criar um sistema de arquivos, etc.), fornecendo uma interface entre o computador e o usuário (português brasileiro) ou utilizador (português europeu). Sistemas operacionais são programas de controle dos recursos do computador, gerenciando eventuais conflitos, e alocando esses recursos da maneira mais eficiente possível. Constituem assim uma forma razoável de tornar os complexos componentes do hardware em algo utilizável na execução de tarefas para o usuário. O computador (pc - personal computer) é constituído por um conjunto de componentes interligados agrupados em três subsistemas básicos (unidades funcionais): CPU, Memória principal e dispositivos de entrada e saída.
Note
Nesse conteúdo, vamos apresentar tudo sobre sistemas operacionais e arquiteturas de máquinas computadorizadas e vamos relacionar com conceitos e práticas da teoria dos autômatos, circuitos integrados, portas lógicas, sistemas embarcados, engenharia reversa, redes de computadores, linguagem de montagem e compiladores.
Tip
Sistemas operacionais são a ponta do iceberg da área de ciência da computação, envolvendo conceitos, técnicas e algoritmos essenciais para desenvolvimentos de arquiteturas e programas de computador.
Embora possa ser executado imediatamente após a máquina ser ligada, a maioria dos computadores pessoais de hoje o executa através de outro programa armazenado em uma memória não-volátil ROM chamado BIOS num processo chamado "bootstrapping", conceito em inglês usado para designar processos autossustentáveis, ou seja, capazes de prosseguirem sem ajuda externa. Após executar testes e iniciar os componentes da máquina (monitores, discos, etc), o BIOS procura pelo sistema operacional em alguma unidade de armazenamento, geralmente o Disco Rígido, e a partir daí, o sistema operacional "toma" o controle da máquina. O sistema operacional reveza sua execução com a de outros programas, como se estivesse vigiando, controlando e orquestrando todo o processo computacional.
Fundamentalmente, um sistema operacional é um software, que pode ser o Linux, Windows, Android, macOS, UNIX, entre outros. No entanto, ele não resume aquilo que seus olhos conseguem ver ou ao que você consegue interagir. Em outras palavras, é um programa que conversa diretamente com o hardware da sua máquina.computadores na década de 1940. Boole por meio de seus estudos com a matemática desenvolve a álgebra booleana a partir dos números binários, isso possibilitou o avanço dos cálculos computacionais, utilizando inicialmente as válvulas, relays e posteriormente em circuitos integrados. São essenciais na criação de servidores.
-
Possuem a finalidade de tornar os complexos computadores em máquinas convenientes para o usuário;
-
Em máquinas eficientes para a resolução de problemas;
-
Facilitar o acesso aos recursos do computador tornando eficiente o uso do hardware, aumentando a produtividade e agilizando as atividades diárias;
-
Garantir a segurança dos dados e sua integridade tanto no armazenamento quanto durante as atividades de processamento, bem como no acesso aos recursos físicos disponíveis.
Histórico dos Sistemas Operacionais: A evolução dos computadores e sistemas de informação no mundo. Desde cálculos até máquinas convencionais
-
5.500 a.C: Ábaco, a primeira calculadora da História.
-
150 a.C. a 100 a.C.: A Máquina de Anticítera (ou Antikythera, em inglês) é considerada o primeiro computador mecânico da história, construído na Grécia Antiga.
-
1638: Régua de Cálculo.
-
1642: Máquina La Pascaline (Máquina de Pascal), de Blaise Pascal, (calculadora mecânica de adição e subtração, a primeira no mundo);
-
1673: Máquina de Gottfried Leibiniz (máquina de somar e multiplicar);
-
1820: Charles Colmar (máquina com quatro operações);
-
1822: Charles Babbage (máquina de cálculos de equações polinomiais);
-
1833: Babbage (máquina para qualquer tipo de operação, máquina analítica - Analytical Engine)
-
1842: Babbage realizou um seminário sobre sua máquina Analítica, que posteriormente foi publicado em francês, contudo ele solicitou ajuda a Ada Lovelace, "Augusto Ada Byron" foi a 1° programadora da história, para traduzir em inglês e adicionar comentários sobre sua máquina no documento. Ada classificou alfabeticamente seus comentários. A máquina analítica foi reconhecida como o primeiro modelo de máquina programável e os comentários de Ada, como a primeira sequência de instruções ou algoritmo.
-
1854: George Boole - Lógica Booleana (
OR,AND,NOT-True/False) base do modelo de computação digital até hoje. Conceito de lógica binária (relés e válvulas) - computadores na década de 1940. Boole por meio de seus estudos com a matemática desenvolve a álgebra booleana a partir dos números binários, isso possibilitou o avanço dos cálculos computacionais, utilizando inicialmente as válvulas, relays e posteriormente em circuitos integrados. -
1889: O norte-americano Herman Hollerith fundador da Tabulating Machine Company, precursora da International Business Machine (IBM), e o engenheiro mecânico francês Joseph Marie Jacquard desenvolveram cartões perfurados, esses cartões guardavam informações e comandos nas máquinas.
-
1935-1938: 1° computador eletromecânico a utilizar binário foi o modelo Z1 criado pelo engenheiro alemão Konrad Zure entre 1935 e 1938 durante a Segunda Guerra, o computador trabalhava com lógica booleana utilizando um sistema de relays.
-
1937: Na universidade de Harvard foi projetado o Automatic Sequence Controlled Calculator (ASCC), um computador capaz de executar as quatro operações fundamentais de aritmética, logaritmos, potenciação, razão de seno e raiz quadrada com autoria do físico Howard Aiken.
-
1939: Segunda Guerra Mundial (Aliados x Eixo). Nesse tempo, a informática teve um papel fundamental, os computadores foram desenvolvidos para calcular estratégias, e descriptografar mensagens dos inimigos mais rápidos que o ser humano.
-
1941: Modelo Z3 e Bombe; A Bombe (Bomba eletromecânica) foi feita para decifrar as mensagens nazistas baseadas em uma linguagem de símbolos Enigma. O Bombe britânico foi concebido pelo engenheiro Harold Keen e Alan Turing da BTMC (British Tabulating Machine Company).
-
1943-1945: Colossus, computador usado para decriptografar os complexos símbolos de Lorenz S2-40 utilizado pelos nazistas, ele era um computador que utilizava em média 2500 válvulas para computar lógica booleana, sendo o primeiro computador eletrônico digital programável.
-
1943-1945: O computador Eletronic Numeral Integrator and Computer (ENIAC) feito por John Mauchly e J Presper Eckert na Escola Moore, foi desenvolvido com tecnologia eletrônica, mil vezes mais rápida que a eletromecânica. Usou fiação de válvulas termiônicas (ou válvulas eletrônicas), que substituíam os relés eletromecânicos usados em máquinas anteriores. Essas válvulas permitiam a amplificação e comutação de sinais eletrônicos, o que fez com que o ENIAC fosse cerca de mil vezes mais rápido do que os computadores eletromecânicos da época.
-
1959: Guerra fria, após o fim da Segunda Guerra Mundial, novas tecnologias foram criadas, como a Memória RAM, UNIVAC I, silício para criação de semicondutores, discos rígidos, linguagem FORTRAN. Depois dos eventos da Mark I e II, Grace Hopper, matemática da Marinha dos Estados Unidos, começou a trabalhar para a corporação Eckert Mauchly Computer, como matemática sênior e gerenciou a equipe de desenvolvimento do UNIVAC I que foi o primeiro computador que atendeu o mercado industrial, sua estrutura robusta com 5 mil válvulas em operação e pesando aproximadamente 13 toneladas. Criou seu primeiro compilador, o A-O e as primeiras linguagens baseadas em compiladores como o Math-Matic e Flow-Matic, que foram utilizadas na UNIVAC I e também trabalhou no desenvolvimento da linguagem de programação COBOL.
-
Década de 50: Primeiras linguagens de programação: Assembly, Fortran, Algol, Cobol, Evolução dos SOs, incorporam seu próprio conjunto de rotinas para operação de I/O (IOCS), Sistema Operacional Atlas - introduziu a ideia de memória hierarquizada, base do conceito de memória virtual.
-
Década de 60: Circuitos integrados, custo menor de aquisição - difusão do uso de sistemas computacionais em empresas. Substituição de fitas por discos no processo de submissão dos programas juntamente com a multiprogramação, tornou sistemas mais rápidos e eficientes.
-
Década de 70: Nos anos 70, mais especificadamente em 1970, os computadores com memória virtual e com 32 bits foram criados; Em 1971, Intel Corp - seu 1° microprocessador - Intel 4004; Em 1974, Intel Corp - microprocessador Intel 8080 - utilizado no 1° microcomputador - Altair; Em 1976, Steve Jobs e Steve Wozniak produzem o Apple II e 8 bits; 1976, Apple e Microsoft são fundadas o SO dominante é o CP/M da Digital Research; Surge o multiprocessamento nos SO, possibilitando de execução de mais de um programa simultaneamente ou até de um programa por mais de um processador. WANs e LANs são definidas, marco do surgimento dos protocolos de redes de computadores. Os SOs passam a estar intimamente relacionados aos softwares de rede; 1971, Niklaus Wirth desenvolve a linguagem Pascal. 1975, Dennis Ritchie desenvolve a linguagem C e juntamente com Ken Thompson, porta o UNIX para um PDP-11, concebido inicialmente em Assembly.
-
Década de 80: Nos anos 80, em 1981, IBM PC com processador Intel 8088 de 16bits e sistema operacional DOS da Microsoft; Universidade de Berkley desenvolve uma versão do UNIX (Berkley Software Distribution - BSD) e introduziu o protocolo TCP/IP; Evolução da família Intel e surgimento dos primeiros sistemas operacionais gráficos como Windows e OS/2; Surgimento de sistemas operacionais de rede como Novell Netware e Microsoft LAN Manager; A computação quântica começou a tomar forma como campo de estudo na década de 1980, quando cientistas começaram a explorar como os princípios da mecânica quântica poderiam ser aplicados à computação.
-
Década de 90: Nos anos 90, evolução da microeletrônica - desenvolvimento de processadores e memórias mais velozes e baratos, dispositivos de I/O menores, mais rápidos e mais capacidade; Com o advento da Internet e o protocolo TCP/IP, torna-se padrão de mercado e problemas de gerência, segurança e desempenho tornam-se fatores importantes relacionados a SO e à rede; Consolidação de SO com interfaces gráficas (GUI); 1991, Linus Torvalds inicia o Linux e evolui com a colaboração de vários programadores (Kernel, utilitários e aplicativos); 1993, Microsoft lança o Windows NT; Nesta década o Windows e o Unix (HP-UX, IBM-AIX e Sun Solaris) consolidam-se como sistemas corporativos.
-
2000: Nos anos 2000, os sistemas operacionais tornam-se cada vez mais intuitivos e passam a ser proativos, isto é, passam a incorporar mecanismos automáticos de detecção e recuperação de erros; Surgimento do REST API; Sistemas em Cluster; Processamento distribuído; Evolução de redes sem fio (Wi-Fi Wireless) - SO Embarcados em dispositivos como celulares, handhelds e palmtops; A Microsoft unifica suas duas versões e inclui novos recursos tanto para servidores quanto para PCs - Windows 2000 e Windows XP, lançados no início da década, evoluíram para 2003 e Vista; O Linux evolui para tornar-se o padrão de SO de baixo custo, com inúmeras formas de distribuições; Processadores 64 bits; Surgimento de softwares que permitem a virtualização de máquinas; Lançamento do Windows 2008 e do Windows 7, plataformas da Microsoft para servidor e computador pessoal, respectivamente, em substituição de suas versões anteriores (2003 e XP); Windows 2008 com virtualização de servidores nativo no sistema operacional, denominado Hyper-V.
-
2025: O primeiro computador biológico de uso comercial do mundo foi lançado pela startup australiana Cortical Labs durante a Mobile World Congress (MCW);
-
Atualmente:
As arquiteturas de hardware juntamente com a evolução dos SOs:
1° Geração (1945 - 1955): Completo acesso ao hardware; Instruções eram introduzidas manualmente, uma a uma, em linguagem de máquina, não existindo, portanto, o conceito de Sistema Operacional; ENIAC, 1943-1946, criado por Eckert, Mauchy e Presper na Pensilvânia, que era um computador que empregava 18.000 válvulas e relés.
Nas primeiras máquinas, a introdução das instruções era por meio de chaveamento de circuitos através de cabos, como nas mesas telefônicas mais antigas.
2° Geração (1955 - 1965): O desenvolvimento do transistor, seu emprego na construção de computadores tornou-os mais baratos e permitiu seu uso comercial. Linguagem de programação de alto-nível, Fortran, e foi desenvolvido o sistema de processamento em batch (lote). A cada lote a ser processado era denominado job, e os sistemas operacionais eram projetados para permitir transição mais fácil entre eles. Quando em execução, um job detinha todo o controle da máquina. Após seu encerramento, o controle era retornado ao SO que procedia a um "clear" total e executava a leitura do próximo job; IBM 701; Para executar uma atividade, o usuário utilizava um formulário de programação, escrevia o seu programa e a seguir, utilizando uma máquina perfuradora, transformava em um conjunto de cartões. IBM 701, para executar uma atividade, o usuário utilizava um formulário de programação, escrevia o seu programa e a seguir, utilizando uma máquina perfuradora, transformava em um conjunto de cartões. Em seguida, os operadores carregavam os cartões perfurados em leitores que os transferiam para fitas magnéticas. As fitas, então, eram lidas pelo computador, que executava um programa por vez, gravando o resultado em uma fita.
Finalmente, a partir do conteúdo da fita era gerado um relatório impressão a ser entregue ao usuário que solicitou o processamento.
3° Geração (1965-1980): esta geração marca o surgimento dos circuitos integrados e da multiprogramação. Ocorreu, em 1965, a introdução no mercado das máquinas IBM/360. Essa geração caracterizou-se pelo surgimento dos sistemas de propósito geral e dos sistemas multimodo. Os computadores desta geração se tornaram mais baratos e rápidos suportando ao mesmo tempo o processamento em lotes, multiprocessamento com atendimento de terminais interativos e também, aplicações de tempo real. Foi desenvolvido nesta época, também, o Sistema Operacional UNIX.
Técnicas desses SOs:
-
Alocação de memória: A memória do sistema é dividida em várias partições nas quais diferentes programas eram carregados de forma que vários deles pudessem utilizá-la de forma concorrente;
-
Spooling: enquanto um job (tarefa) era executado, os cartões de outros jobs eram lidos e transferidos para o disco. Isso permitia que a troca entre os diversos jobs ocorresse de forma mais rápida, já que o acesso ao disco era muito mais rápido que a leitura dos cartões;
-
Time sharing: cada programa, na memória, utilizava o processador em pequenos intervalos de tempo, isso permitia que, enquanto uma tarefa esperava alguma operação de Entrada ou Saída, outra utilizasse o processador (CPU).
4° Geração (1980 até Hoje): Surgimento da integração em larga escala e dos computadores pessoais. A integração em larga escala permitiu que a CPU do computador fosse construída em um único chip de silício barateando o seu custo e permitindo o surgimento dos computadores pessoais. O surgimento dos microcomputadores levou à criação de toda uma nova geração de SOs. Como então qualquer pessoa poderia ter um computador, o SO teve que se adaptar, fornecendo mais interatividade, evoluindo das interfaces, em texto, como o DOS para as interfaces gráficas como o Windows.
O sistema operacional proporciona o ambiente no qual os programas são executados e é composto por um conjunto de rotinas, conhecido como o núcleo (kernel). O Kernel padrão, é chamado de kernel monolítico , nele o sistema operacional é escrito como uma coleção de rotinas, ligadas a um único grande programa binário executável. O kernel monolítico executa cada serviço do sistema como gerenciamento de memória, manipulação de interrupções e comunicação I/O, sistemas de arquivos, no espaço do kernel.
Temos também o microkernel que é uma abordagem de arquitetura de sistemas operacionais onde apenas os componentes essenciais do sistema rodam no kernel — como a comunicação entre processos, gerenciamento de memória e controle de hardware básico. Tudo o mais, como drivers de dispositivos, sistemas de arquivos e até a pilha de rede, é mantido fora do kernel, operando em espaço de usuário como serviços separados.
O conceito do microkernel é de reduzir o kernel a comunicação de processos básicos e o controle de I/O, e deixar os outros serviços de sistemas situados no user-space (espaços de usuário) em forma de processos normais (chamados de servers).
Isso traz algumas vantagens:
- Mais estabilidade e segurança, porque um erro em um componente fora do núcleo tem menos chance de derrubar o sistema inteiro.
- Maior modularidade, facilitando atualizações e manutenção.
- Portabilidade, já que o microkernel é pequeno e mais fácil de adaptar a diferentes arquiteturas.
No entanto, ele também pode ser mais lento em certas operações, pois exige mais trocas de contexto entre o núcleo e os serviços no espaço do usuário.
Ele é aplicado principalmente em:
- Sistemas embarcados, como dispositivos médicos, automóveis e aviônicos, onde confiabilidade é crucial.
- Sistemas que exigem alto grau de segurança, como projetos militares e governamentais.
- Alguns projetos acadêmicos e de pesquisa também gostam de explorar microkernels como forma de experimentar novas ideias de sistema operacional.
Um bom exemplo real é o seL4, um microkernel focado em segurança formalmente verificada.
A interface entre o Sistema Operacional e os programas dos usuários é definida por um conjunto de instruções denominado chamadas de sistema (System Calls). As system calls constituem a interface entre um programa do usuário e o Sistema Operacional. Elas podem ser entendidas como uma porta de entrada de acesso ao núcleo do sistema, que contém suas funções. Sempre que o usuário necessitar de algum serviço, solicita-o através de uma chamada de sistema definida e específica.
Os tipos de sistemas operacionais são classificados como: Sistemas monoprogramáveis ou monotarefas, sistemas multiprogramáveis ou multitarefas e sistemas multiprocessadores.
Sistema monoprogramado ou monotarefa o sistema computacional fica totalmente dedicado a um único programa, ou seja, todos os recursos e dispositivos ficam o tempo todo disponíveis ao programa que está sendo executado, mesmo que o dispositivo não esteja sendo utilizado. Por exemplo, se o programa está fazendo uma operação de entrada e saída o processador, apesar de ocioso, não pode ser utilizado para outra tarefa.
Características:
- Esta era a configuração típica dos primeiros SO;
- Este tipo de SO pode atender a apenas um único usuário de cada vez;
- Este tipo de SO é relativamente simples de ser implementado.
Inicialmente, os SO eram monotarefas, ou seja, apenas uma tarefa (programa) era executada de cada vez. Com a evolução dos sistemas computacionais, os SOs também evoluíram no sentido de dar suporte à execução de várias tarefas ao mesmo tempo, de forma real em sistemas com múltiplos processadores, ou de forma concorrente em sistemas com um único processador, por meio de multiprogramação. Para dar conta dessa situação, os projetistas de Sistemas Operacionais desenvolveram o conceito de processo.
Para que a execução de várias tarefas seja possível, é necessário o monitoramento das múltiplas atividades entre os vários programas, tarefa difícil e bastante complexa.
Sistema multiprogramado ou multitarefa são os mais complexos que os sistemas monoprogramáveis, os diversos recursos computacionais são compartilhados pelas várias tarefas ou programas, a execução concorrente de processos. Neste tipo, o SO deve gerenciar a alocação dinâmica dos recursos do computador às diversas demandas geradas pelas tarefas. Todo SO multiusuário é ao mesmo tempo um sistema multitarefa.
O SO terá que gerenciar o acesso concorrente aos componentes do sistema, protegendo os dados de cada programa e evitando que as ações de uma tarefa prejudique as outras. Este tipo de SO aumenta a produtividade e reduz os custos de utilização, pois enquanto um programa realiza uma operação de entrada e saída outro pode utilizar o processador.
Quanto ao suporte aos usuários, pode ser classificado como:
-
Monousuário apenas um usuário utiliza o sistema por vez.
-
Multiusuário vários usuários podem executar o sistema ao mesmo tempo.
Sistemas desse tipo podem suportar várias formas de processamento:
-
Sistemas Batch: como os utilizados na segunda geração de computadores. Este tipo não necessita da interação do usuário, já que o programa é executado sequencialmente após a sua carga que era realizada a partir de fitas ou discos.
-
Sistemas de tempo compartilhado (time sharing): O tempo de uso do processador é dividido em pequenas fatias atribuídas a cada programa, permitindo assim que diversas tarefas sejam executadas. O usuário tem a impressão de que o sistema está todo dedicado ao seu trabalho e desta forma o SO permite que vários usuários o utilizem ao "mesmo tempo". Um sistema operacional que trabalha com multiprogramação é classificado como sistema de tempo compartilhado.
-
Sistemas de tempo real: Diferem dos sistemas de tempo compartilhado por suas aplicações possuírem um tempo máximo aceitável para produzir a resposta.
Sistemas multiprocessados caracterizam-se por possuírem vários processadores que trabalham em conjunto e compartilham dados. Desta forma, permitem que vários programas sejam, verdadeiramente, executados simultaneamente, sendo assim multiusuários.
Este tipo de sistema, além dos benefícios da multiprogramação, possui outras vantagens específicas como:
-
Estabilidade: Ampliar a capacidade computacional acrescentando mais processadores.
-
Disponibilidade: Se um processador falhar os outros podem manter o sistema ativo.
-
Balanceamento de carga: Distribuir as tarefas entre os varios processadores a partir da carga de trabalho de cargo um, ocupando a capacidade ociosa e melhorando o desempenho total do sistema.
Podem ser:
-
Fortemente acoplados: os sistemas multiprocessados compartilham uma única memória e são controlados pelo mesmo SO. Como por exemplo, podemos citar modelos de modernos PCs com vários chips de processadores ou os chips com vários nucleos como os I3, I5 e I7 da Intel.
-
Fracamente acoplados: os processadores não estão em um único computador, mas espelhados em máquinas diferentes, cada uma com o seu SO. Estes computadores são ligados por uma linha de comunicação. Como exemplo, temos os servidores e os clientes de uma rede de computadores. Exemplos deste tipo são os Sistemas Operacionais de Redes e os Sistemas distribuídos.
Portanto, para criar um sistema operacional do zero — partindo do zero mesmo, como no estilo dos kernels tipo Unix, Linux, Minix, ou mesmo kernels experimentais — é necessário, sim, ter domínio de praticamente toda essa base descrita. Isso porque um sistema operacional é o elo direto entre o hardware cru e os softwares que rodam sobre ele. Ele gerencia a CPU, memória, dispositivos de E/S, processos, arquivos e até redes — tudo isso exigindo conhecimento profundo de múltiplas camadas da computação.
Começando por arquitetura de computadores, você precisa entender como o processador funciona, como ele lê instruções, acessa a memória, manipula interrupções e executa código binário. Sem isso, não há como escrever o bootloader ou um kernel funcional. A linguagem de montagem (Assembly) entra nesse ponto como ferramenta obrigatória para inicializar o processador, configurar registradores, pilha e chamar instruções específicas antes de passar o controle para algo em C ou C++.
A seguir, entram os conceitos de compiladores e linkers: você precisa saber como seu código será traduzido para binário, como o loader irá interpretá-lo, e como o SO vai organizar símbolos, tabelas e chamadas. Esse conhecimento é fundamental até para construir um simples carregador de arquivos .elf ou lidar com o layout da memória no tempo de boot.
Teoria dos autômatos, embora pareça distante, é essencial nos bastidores: os conceitos de máquina de estados, análise léxica e sintática são usados em shells, interpretadores, gerenciadores de tarefas, sistemas de arquivos e até em drivers que interagem com hardware de forma controlada.
Portas lógicas e circuitos integrados te conectam ao nível elétrico da computação. Embora você não vá soldar chips ao criar um SO, entender como bits são representados fisicamente, como interrupções são geradas eletricamente e como o processador interage com a memória e com o barramento é indispensável para entender, por exemplo, o mapeamento de memória, o acesso direto à hardware (como VGA, UART) ou o uso de I/O-mapped devices.
Sistemas embarcados são praticamente sistemas operacionais minimalistas em si. Criar um SO para embarcados exige, além da base tradicional, conhecimento sobre gerenciamento de energia, controle em tempo real, escalonamento determinístico e drivers com restrições de espaço, RAM e processamento.
Engenharia reversa não é usada para criar do zero, mas ajuda imensamente a aprender com quem já criou. Você pode estudar kernels como o Linux, OpenBSD ou projetos como os kernels experimentais do GitHub para ver como o boot, o gerenciamento de processos, a organização da memória virtual e a pilha de rede foram implementados. Muitos aprendem a escrever SOs justamente desmontando outros.
Por fim, redes de computadores entram como uma das funcionalidades mais avançadas. Para um SO se comunicar, ele precisa de uma pilha de rede própria, que lida com pacotes, buffers, protocolos e drivers de interface. Implementar isso requer não só domínio de protocolos como TCP/IP, mas também acesso baixo nível ao hardware da placa de rede.
Então sim — a interligação de todos esses campos é praticamente obrigatória para construir um sistema operacional real, mesmo que mínimo. Claro que você pode começar pequeno: um bootloader que imprime uma mensagem na tela, depois um scheduler simples, depois um gerenciador de memória rudimentar... Mas com o tempo, todos esses domínios se entrelaçam. Você não precisa dominar tudo de cara, mas sim entender que criar um SO exige conhecimento que atravessa toda a base estrutural da ciência da computação.

Um programa é um conjunto de instruções, também conhecidas como algoritmos, que descrevem uma tarefa a ser realizada por um computador. O termo pode ser uma referência ao código fonte, escrito em alguma linguagem de programação, ou ao arquivo que contém a forma executável deste código fonte. Um programa torna um computador utilizável, sem ele um computador, mesmo o mais poderoso, nada mais é do que um objeto.
Os computadores são capazes de executar tarefas muito complexas, mas essa capacidade não lhes é inata. A natureza de um computador é bastante diferente. Ele só pode executar operações extremamente simples, por exemplo, um computador não pode avaliar o valor de uma função matemática complicada por si só, embora isto não esteja fora do âmbito das possibilidades num futuro próximo.
Os computadores contemporâneos só podem avaliar os resultados de operações muito fundamentais, como adicionar ou dividir, mas podem fazê-lo muito rapidamente, e podem repetir estas ações virtualmente um qualquer número de vezes.
As Lógica de programação é a habilidade de organizar pensamentos computacionais, habilidades técnicas e pessoais (Hard e Soft Skills) e instruções de forma lógica e estruturada, essencial para resolver problemas e criar algoritmos que possam ser entendidos e executados por um computador. É como construir um mapa claro e sequencial de passos para atingir um objetivo, usando raciocínio lógico, condicionais, loops e operações para criar um conjunto de instruções compreensível e eficiente para resolver um problema computacional.
Há uma relação entre a lógica de programação e as regras de negócio. A lógica de programação é fundamental para traduzir as regras de negócio em instruções lógicas e algoritmos compreensíveis para o computador. As regras de negócio representam as diretrizes, restrições e condições que definem como um negócio deve operar, incluindo políticas, procedimentos, metodologias, processos, contratos e operações específicas. A lógica de programação ajuda a implementar essas regras de negócio no código, permitindo que os desenvolvedores convertam os requisitos e as lógicas do mundo real em algoritmos que o computador possa entender e executar. Isso envolve a criação de estruturas condicionais, loops, operações lógicas e matemáticas que representam fielmente as regras de negócio.
Assim, a habilidade de compreender as regras de negócio e traduzi-las adequadamente para o código por meio da lógica de programação é crucial para o desenvolvimento de sistemas de software que atendam às necessidades e expectativas de uma empresa ou projeto.
Os algoritmos são um conjunto de instruções ou regras bem definidas, que são usadas para resolver um problema ou realizar uma tarefa. Eles são usados na ciência da computação para descrever a sequência de passos que um computador deve seguir para realizar uma determinada operação, como realizar um cálculo matemático, ordenar uma lista de dados, realizar uma pesquisa na internet, consultar dados, criar interfaces ou construir uma API. Então, um algoritmo é um conjunto de instruções, passos ou regras bem definidas e finitas, que quando são estruturados e organizados são usados para resolver um determinado problema ou realizar uma tarefa computacional de qualquer nível de complexidade, dependendo das situações que o dispositivo operar e corresponder a elas. E, portanto, o esboço de um algoritmo é gerado através de um pensamento computacional, organização de ideias, prototipagem/documentação, processos de entrega (DevSecOps), sistema de controle de versões e lógica matemática. Tudo vem na mente para depois ser escrito no papel e depois na máquina com regras de input (entrada) e output (saída) para compilação ou interpretação da máquina.
O pensamento computacional é o processo de pensamento envolvido na formulação de um problema e na expressão de sua solução de forma que um computador humano ou máquina possa efetivamente realizar.
Os algoritmos são usados em muitas áreas diferentes, incluindo ciência da computação, matemática, engenharia, física e biologia. Eles são a base para muitos programas de computador e sistemas automatizados, e são essenciais para muitas tarefas complexas que requerem uma sequência de operações precisas. Algoritmos também são usados em inteligência artificial e aprendizado de máquina, onde são usados para ensinar computadores a aprender e tomar decisões com base em dados.
Podemos dizer que Algoritmos é o "ABC", ou seja a base, da área de ciência da computação que todo desenvolvedor de software deveria saber antes de desenvolver sistemas complexos.
Um software é um conjunto integrado de programas de computador. Um programa de computador é um conjunto de instruções que descreve, passo a passo, uma tarefa que deve ser realizada pelo hardware.
Exemplo: Software de Gestão Escolar = conjunto de programas que executam um conjunto de tarefas necessárias a gestão de uma escola. Dentro do Software de Gestão Escolar, temos o programa que calcula a média dos alunos, com base nas notas informadas das provas.
Para o desenvolvimento dos programas que integram o software precisamos de uma linguagem de programação, que define as instruções e a forma de relacioná-las.
A primeira linguagem de programação gerava programas, em código de máquina (sequência de 0 e 1), mas era muito difícil para o programador que teria que escrever um código binário (0 ou 1), memorizar as instruções em sequencias de 0 e 1.
A partir daí, diferentes linguagens de programação foram criadas, sempre almejando conceder poder e facilidade ao programador. Eram as linguagens de programação de alto nível (receberam esse nome por serem bem próximas da linguagem natural do homem).
Mas o Hardware somente entende a linguagem binária, assim sendo, o programa escrito em linguagem de alto nível precisa passar por um processo adicional, que converta a linguagem de alto nível em linguagem de máquina para ser compreendida e executada pelo hardware.
Vamos ver agora exemplos de algoritmos abaixo:
Exemplo 1: Somando dois números
- Digite o primeiro número:
- Digite o segundo número:
- Some os dois números escolhidos.
- Exiba o resultado da soma:
Exemplo 2: Atravessar a rua
- Encontre uma faixa de pedestres ou uma interseção controlada por semáforo.
- Pare na calçada e aguarde a luz verde do semáforo de pedestres ou o sinal de pedestre indicando que é seguro atravessar.
- Olhe para a esquerda, para a direita e depois para a esquerda novamente para garantir que nenhum veículo esteja se aproximando.
- Comece a atravessar a rua, mantendo-se na faixa de pedestres e continue a olhar para a esquerda e para a direita enquanto atravessa.
Exemplo 3: Cubo Mágico
Resolver o cubo mágico é um desafio emocionante que pode ser alcançado com a prática e o uso de algoritmos adequados. Com a estratégia certa e a persistência, qualquer pessoa pode dominar a arte da resolução do cubo mágico.
Existem várias maneiras de resolver o cubo mágico, mas o método mais comum é o método Camadas, usando algoritmos que envolve a resolução do cubo em camadas, uma por vez.
A lógica de programação é essencial para um desenvolvedor, imagine que quer saber a velocidade média que alcançou durante uma longa viagem. Sabe a distância, sabe o tempo, precisa da velocidade. Naturalmente, o computador será capaz de calcular isto, mas o computador não está ciente de coisas como distância, velocidade ou tempo. Portanto, é necessário instruir o computador a:
- Aceitar um número que represente a distância;
- Aceitar um número que represente o tempo de viagem;
- Dividir o valor anterior pelo último e armazenar o resultado na memória;
- Exibir o resultado (representando a velocidade média) num formato legível.
Estas quatro simples ações formam um programa. É claro que estes exemplos não são formalizados, e estão muito longe do que o computador pode compreender, mas são suficientemente bons para serem traduzidos para uma linguagem que o computador possa aceitar.
Uma Linguagem (Language), nossa palavra-chave, é um meio (e uma ferramenta) para expressar e registar pensamentos. Há muitas linguagens ao nosso redor e algumas delas não requerem nem a fala nem a escrita, como a linguagem corporal; é possível expressar os seus sentimentos mais profundos com muita precisão sem dizer uma palavra.
Outra linguagem que usa diariamente é a sua língua materna, que usa para manifestar a sua vontade e para pensar na realidade. Os computadores também têm a sua própria linguagem, chamada linguagem de máquina, que é muito rudimentar. O código de máquina ou linguagem de máquina é uma linguagem de programação de baixo nível, constituída por dígitos/bits binários que o computador lê e compreende, ou seja, é um conjunto de instruções executadas diretamente pela unidade de processamento central (CPU) de um computador. Cada instrução executa uma tarefa muito específica, como uma carga, um salto ou uma operação ALU em uma unidade de dados em um registrador ou memória da CPU. Todo programa executado diretamente por uma CPU é composto por uma série de tais instruções. O código de máquina numérico pode ser considerado como a representação de nível ainda mais baixo de um programa de computador compilado e/ou montado ou como uma linguagem de programação primitiva e dependente de hardware. Embora seja possível escrever programas diretamente em código de máquina numérico, é tedioso e propenso a erros gerenciar bits individuais e calcular endereços numéricos e constantes manualmente. Portanto, raramente é feito hoje, exceto em situações que exigem otimização ou depuração extremas.
Note
O código de máquina numérico (machine code) não é o código ou linguagem de montagem, conhecida como Assembly ou Assembler, cujo é uma linguagem de programação de baixo-nível superior.

010010101010010
010010100110100
010101100111010
010101010101011
010101010100101
010101010010111
Note
As linguagens de máquina são desenvolvidas por humanos e não pela própria máquina.
Um computador, mesmo o mais sofisticado tecnicamente, é desprovido até mesmo de um vestígio de inteligência. Esse é um assunto muito abordado quando estudamos para Inteligência Artifical e Machine Learning.
Pode-se dizer que é como um 🐵 macaco bem treinado - responde apenas a um conjunto pré-determinado de comandos conhecidos. Os comandos que reconhece são muito simples. Podemos imaginar que o computador responde a ordens como "pega nesse número, divide-o por outro e guarda o resultado".
Um conjunto completo de comandos conhecidos é chamado de lista de instruções, por vezes abreviado para IL (do inglês, Instruction List). Os diferentes tipos de computadores podem variar em função do tamanho das suas IL, e as instruções podem ser completamente diferentes em diferentes modelos.
Atualmente, nenhum computador é capaz de criar uma nova linguagem. No entanto, isso pode mudar em breve. Por outro lado, as pessoas também utilizam uma série de línguas muito diferentes, mas estas línguas desenvolveram-se naturalmente. Além disso, ainda estão a evoluir. São criadas novas palavras todos os dias e as palavras antigas desaparecem. Estas línguas são chamadas linguagens naturais.
Podemos dizer que cada linguagem (de máquina ou natural, não importa) é constituída pelos seguintes elementos:
-
um alfabeto: um conjunto de símbolos utilizados para construir palavras de uma determinada linguagem (por exemplo, o alfabeto latino para inglês, o alfabeto cirílico para russo, o Kanji para japonês, etc.)
-
um lexis: (ou seja, um dicionário) um conjunto de palavras que a linguagem oferece aos seus utilizadores (por exemplo, a palavra "computador" vem do dicionário de língua inglesa, enquanto que "cmoptrue" não; a palavra "chat" está presente tanto nos dicionários de inglês como de francês, mas os seus significados são diferentes)
-
uma sintaxe: um conjunto de regras (formais ou informais, escritas ou sentidas intuitivamente) utilizadas para determinar se uma determinada sequência de palavras forma uma frase válida (por exemplo, "Eu sou uma pitão" é uma frase sintaticamente correta, enquanto "Eu uma pitão sou" não é)
-
semântica: um conjunto de regras que determinam se uma determinada frase faz sentido (por exemplo, "Comi um donut" faz sentido, mas "Um donut comeu-me" não faz)
O IL é, de facto, o alfabeto de uma linguagem de máquina. Este é o conjunto mais simples e primário de símbolos que podemos utilizar para dar comandos a um computador. É a língua materna do computador. Infelizmente, esta língua está muito longe de ser uma língua materna humana. Todos nós (tanto computadores como humanos) precisamos de algo mais, uma linguagem comum para computadores e humanos, ou uma ponte entre os dois mundos diferentes.
Precisamos de uma linguagem em que os humanos possam escrever os seus programas e uma linguagem que os computadores possam utilizar para executar os programas, uma linguagem que seja muito mais complexa do que a linguagem das máquinas e, no entanto, muito mais simples do que a linguagem natural.
Tais linguagens são muitas vezes chamadas linguagens de programação de alto nível. São pelo menos um pouco semelhantes aos naturais na medida em que utilizam símbolos, palavras e convenções legíveis para os seres humanos. Estas linguagens permitem aos seres humanos expressar comandos a computadores que são muito mais complexos do que os oferecidos pelas ILs. Um programa escrito numa linguagem de programação de alto nível é chamado source code, também conhecido como código-fonte (em contraste com o ee executado por computadores). Da mesma forma, o ficheiro que contém o source code chama-se source file, també conhecido como arquivo-fonte. A programação informática é o ato de compor os elementos da linguagem de programação selecionada pela ordem que provocará o efeito desejado. O efeito pode ser diferente em cada caso específico - depende da imaginação, conhecimento e experiência do programador.
É claro que tal composição tem de ser correta em muitos sentidos:
-
alfabeticamente - um programa precisa de ser escrito num guião reconhecível, tal como romano, cirílico, etc.
-
lexicamente - cada linguagem de programação tem o seu dicionário e é preciso dominá-lo; felizmente, é muito mais simples e menor do que o dicionário de qualquer língua natural;
-
sintaticamente - cada linguagem tem as suas regras, e estas devem ser obedecidas;
-
semanticamente - o programa tem de fazer sentido.
Infelizmente, um programador também pode cometer erros com cada um dos quatro sentidos acima referidos. Cada um deles pode fazer com que o programa se torne completamente inútil.
Vamos supor que tenha escrito um programa com sucesso. Como persuadir o computador a executá-lo? Tem de transformar o seu programa em linguagem de máquina. Felizmente, a tradução pode ser feita pelo próprio computador, tornando todo o processo rápido e eficiente.
Há duas formas diferentes de transformar um programa de uma linguagem de programação de alto nível em linguagem de máquina:
-
COMPILAÇÃO - o source program é traduzido uma vez (no entanto, este ato deve ser repetido sempre que modificar o source code) obtendo um ficheiro (por exemplo, um
ficheiro.exese o código se destinar a ser executado no MS Windows) contendo o machine code; agora pode distribuir o ficheiro por todo o mundo; o programa que executa esta tradução chama-se compilador ou tradutor; -
INTERPRETAÇÃO - você (ou qualquer utilizador do código) pode traduzir o source program cada vez que este tem de ser executado; o programa que executa este tipo de transformação chama-se intérprete ou interpretador, pois interpreta o código cada vez que se pretende executá-lo; também significa que não pode simplesmente distribuir o source code tal como está, porque o utilizador final também precisa do intérprete para o executar.
Aprenda mais: O interpretador converte para código de máquina, em tempo de execução. O compilador traduz o programa inteiro em código de máquina e o executa, gerando um arquivo que pode ser executado. O compilador gera um relatório de erros e o interpretador interrompe o processo na medida em que localiza um erro.
Devido a algumas razões muito fundamentais, uma linguagem de programação particular de alto nível foi concebida para se enquadrar numa destas duas categorias.
Há muito poucas linguagens que possam ser compiladas e interpretadas. Normalmente, uma linguagem de programação é projetada com este fator na mente dos seus construtores - será ela compilada ou interpretada?
Vamos assumir mais uma vez que escreveu um programa. Agora, existe como um ficheiro de computador (computer file): um programa de computador é na realidade um pedaço de texto, por isso o source code é normalmente colocado em ficheiros de texto (text files).
Nota: tem de ser texto puro, sem quaisquer decorações como diferentes fontes, cores, imagens embutidas ou outros suportes. Agora tem de invocar o intérprete e deixá-lo ler o seu source file.
O intérprete lê o source code de uma forma que é comum na cultura ocidental: de cima para baixo e da esquerda para a direita, porém há algumas exceções.
Em primeiro lugar, o intérprete verifica se todas as linhas subsequentes estão corretas (utilizando os quatro aspetos abordados anteriormente). Se o compilador encontrar um erro, termina o seu trabalho imediatamente. O único resultado, neste caso, é uma mensagem de erro.
Em linguagem de máquina, iria corresponder:
Abstração é o processo de identificação das qualidades e/ou propriedades relevantes para o contexto que está sendo analisado e desprezando o que seja irrelevante. Um modelo é uma abstração da realidade.
Um programa de computador é um modelo, pois representa a solução de um problema em termos algorítmicos. Assim sendo, a abstração permeia toda a atividade de programação de computadores.
A linguagem de máquina foi a primeira a ser criada para a prática de programação. Trata-se da linguagem nativa do computador, a única que ele, de fato, compreende. Uma linguagem muito complicada para ser entendida pelas pessoas, em que um comando que soma 2 números, é formado por uma sequência de 1 e 0, muito difícil de ser memorizada, usada e, mais ainda, de ser entendida por terceiros.
As primeiras linguagens de programação, porém, não reconheciam o papel crucial que a abstração desempenha na programação. Por exemplo, no início da década de 1950, o único mecanismo de abstração fornecido pela linguagem de montagem, ou Assembly, em relação às linguagens de máquina eram os nomes simbólicos.
Você sabia? : O programador podia empregar termos relativamente autoexplicativos (nomes simbólicos) para nomear códigos de operação (ADD = soma, SUB = subtração, M = multiplicação e DIV = divisão) e posições de memória. A linguagem de montagem (Assembly) melhorou a vida do programador, porém obrigava-o a escrever 1 linha de código para cada instrução que a máquina deve executar, forçando-o a pensar como se fosse uma máquina.
Um pouco mais adiante, visando a aumentar o poder de abstração das linguagens de forma a permitir uma melhor performance dos programadores, surgem as linguagens de alto nível, próximas à linguagem humana e mais distantes das linguagens Assembly e de máquina.
A tabela, a seguir, exibe, à esquerda, um programa-fonte, escrito numa linguagem de alto nível, a linguagem Python. Ao centro, temos o código equivalente na linguagem Assembly para o sistema operacional Linux e, à direita, o respectivo código na linguagem de máquina, de um determinado processador. Observe:
| Linguagem Python | Linguagem Assembly | Linguagem de Máquina |
def swap(self, v, k):
temp = self.v[k];
self.v[k] =
self.v[k+1];
self.v[k+1]= temp;
|
swap:
Muli $2,$5,4
Add $2,$4,$2
Lw $15,0($2)
Lw $16,4($2)
Sw $16,0($2)
Sw $15,4($2)
Jr $31
|
00000000001111111111100000000001
00011111111000000111000011111101
11111000001100000111111110000000
10000000100000001000000010000000
00000000010000000001000000000010
00000000000000001111000010010101
00000000111000111111001111111111
|
A imagem abaixo ilustra o conceito de abstração, em que a partir da linguagem de máquina, cria-se camadas (de abstração) para facilitar a vida do programador.
A imagem representa o crescimento do nível de abstração:

- É representado pelo hardware, conjunto de circuitos eletrônicos.
- É representado pela linguagem de máquina (1 e 0), única que o hardware entende.
- É representado pela linguagem Assembly (mneumônicos).
- É representado pelas linguagens de alto nível, próximas à língua do usuário e distantes da linguagem computacional. Python e Java são linguagens de programação representativas da classe LP de alto nível (LP = Linguagem de Programação).
Por que estudar linguagens de programação? O estudante e/ou programador que se dispuser a gastar seu tempo aprendendo linguagens de programação terá as seguintes vantagens:
- Maior capacidade de desenvolver soluções em termos de programas — compreender bem os conceitos de uma LP pode aumentar a habilidade dos programadores para pensar e estruturar a solução de um problema.
- Maior habilidade em programar numa linguagem, conhecendo melhor suas funcionalidades e implementações, ajuda para que o programador possa construir programas melhores e mais eficientes. Por exemplo, conhecendo como as LPs são implementadas, podemos entender melhor o contexto e decidir entre usar ou não a recursividade, que se mostra menos eficiente que soluções iterativas.
- Maiores chances de acerto na escolha da linguagem mais adequada ao tipo de problema em questão, quando se conhece os recursos e como a linguagem os implementa. Por exemplo, saber que a linguagem C não verifica, dinamicamente, os índices de acesso a posições de vetores pode ser decisivo para sua escolha em soluções que usem frequentemente acessos a vetores.
- Maior habilidade para aprender novas linguagens. Quem domina os conceitos da orientação a objeto, tem mais aptidão para aprender Python, C++, C# e Java.
- Amplo conhecimento dos recursos da LP reduz as limitações na programação.
- Maior probabilidade para projetar novas LP, aos que se interessarem por esse caminho profissional: participar de projetos de criação de linguagens de programação.
- Aumento da capacidade dos programadores em expressar ideias. Em geral, um programador tem expertise em poucas variedades de linguagens de programação, dependendo do seu nicho de trabalho. Isso, de certa forma, limita sua capacidade de pensar, pois ele fica restrito pelas estruturas de dados e controle que a(s) linguagem(ns) de seu dia a dia permitem. Conhecer uma variedade maior de recursos das linguagens de programação pode reduzir tais limitações, levando, ainda, os programadores a aumentar a diversidade de seus processos mentais.
Quanto maior for o leque de linguagens que um programador dominar e praticar, maiores as chances de conhecer e fazer uso das propriedades superlativas da(s) linguagem(ns) em questão.
Ao longo dos anos, os autores têm criado diferentes classificações para as linguagens de programação, usando critérios diferenciados e agrupando-as sob diferentes perspectivas.
Veremos a seguir as classificações das linguagens por nível, por gerações e por paradigmas.
A classificação por nível considera a proximidade da linguagem de programação com as características da arquitetura do computador ou com a comunicação com o homem.
Linguagem de baixo nível são linguagens que se aproximam da linguagem de máquina, além da própria, que se comunicam diretamente com os componentes de hardware, como processador, memória e registradores. As linguagens de baixo nível estão relacionadas à arquitetura de um computador.
São linguagens escritas usando o conjunto de instruções do respectivo processador. Ou seja, cada processador diferente (ou família de processador, como os I3, I5 e I7 da Intel) tem um conjunto de instruções específicos (instructions set).
Abaixo, a imagem ilustra a representação de uma instrução em linguagem de máquina ou binária de um processador específico. A instrução tem palavras (unidade executada pelo processador) de 16 bits, sendo 4 bits para representar a instrução (código da instrução), 6 bits para representar cada operando.
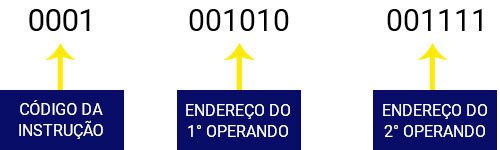
Instrução em linguagem de máquina: Imagine, agora, uma sequência de 0 e 1 para que possamos dizer ao processador cada ação que deve ser realizada conforme ilustrado abaixo.
0001001010001111
1010010001000010
0010101110110111
0101010000000111
Era de fato muito complexa a programação na linguagem de máquina, a linguagem nativa dos processadores.
Essa complexidade motivou o desenvolvimento da linguagem Assembly, que deixava de ser a linguagem nativa dos processadores, mas usava das instruções reais dos processadores. Assim, a instrução na linguagem Assembly precisa ser convertida para o código equivalente em linguagem de máquina.
Exemplo: As três linhas de código na linguagem Assembly, abaixo, que move o numeral 2 para o registrador AX (linha 1), move o numeral 1 para o registrador BX (linha 2) e soma o conteúdo dos 2 registradores (linha 3).
MOV AX, 0002
MOV BX, 0001
ADD AX, BXNão chega a ser o ideal em termos de uma linguagem, que é ainda próxima da máquina, mas já foi um grande avanço em relação à memorização da sequência de 0 e 1 de uma instrução de máquina.
Linguagens de baixo nível: estão distantes da língua humana (escrita).
Linguagem de alto nível: No outro extremo das linguagens de baixo nível, estão as linguagens de alto nível, na medida em que se afastam da linguagem das máquinas e se aproximam da linguagem humana (no caso, a linguagem escrita e a grande maioria em Inglês).
Você sabia: Quem programa em uma linguagem de alto nível não precisa conhecer características dos componentes do hardware (processador, instruções e registradores). Isso é abstraído no pensamento computacional.
As instruções das linguagens de alto nível são bastante abstratas e não estão relacionadas à arquitetura do computador diretamente. As principais linguagens são:
Python, ASP, C, C++, C#, Pascal, Delphi, Java, Javascript, Go, Scala, Clojure, Lua, MATLAB, PHP e Ruby, dentre outras.
Abaixo, o mesmo código expresso acima, escrito em Assembly, porém usando variáveis, como abstração do armazenamento e codificado na linguagem Python.
def main(): num1 = 2 num2 = 1 soma = num1 + num2Abaixo, o mesmo código na linguagem C:
int num1, num2, soma; int main() { num1=2; num1=1; soma=num1+num2; }
Cada comando de uma linguagem de alto nível precisa ser convertido e equivalerá a mais de uma instrução primária do hardware. Isso significa que, numa linguagem de alto nível, o programador precisa escrever menos código para realizar as mesmas ações, além de outras vantagens, aumentando consideravelmente a sua eficiência ao programar.
Saiba mais: Há uma curiosidade: C e C++ são classificados por alguns autores como linguagem de médio nível, na medida que estão próximas da linguagem humana (linguagem de alto nível), mas também estão próximas da máquina (linguagem de baixo nível), pois possuem instruções que acessam diretamente memória e registradores. Inicialmente, a linguagem C foi criada para desenvolver o sistema operacional UNIX, que até então era escrito em Assembly.
Outro dado que merece ser comentado é que algumas pessoas consideram a existência de linguagens de altíssimo nível, como Python, Ruby e Elixir, por serem linguagens com uma enorme biblioteca de funções e que permitem a programação para iniciantes sem muito esforço de aprendizado.
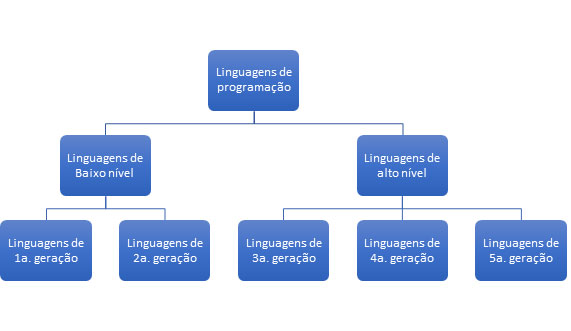
Outra forma de classificar as linguagens, amplamente difundida, é por gerações. Não há um consenso sobre as gerações, alguns consideram 5, outros 6. A cada geração, novos recursos facilitadores são embutidos nas respectivas linguagens.
-
A 1ª geração de linguagens é representa pela linguagem de máquina sendo baixo-nível, nativa dos processadores.
-
As linguagens de segunda geração são denominadas Assembly, sendo baixo-nível, e são traduzidas para a linguagem de máquina por um programa especial (montador), chamado Assembler. A partir dessa geração, toda linguagem vai precisar de um processo de conversão do código nela escrito, para o código em linguagem de máquina.
Acompanhe o exemplo abaixo para uma CPU abstrata. Considere a seguinte sequência de 3 instruções em linguagem Assembly:
| Código em Assembly | O que faz cada linha de código |
Mov #8, A |
Lê um valor da posição de memória 8 para o registrador A |
Mov #9, B |
Lê um valor da posição de memória 9 para o registrador B |
ADD A,B |
Soma os valores armazenados nos registradores A e B |
Em linguagem de máquina, depois de traduzidas pelo Assembler, as instruções poderiam ser representadas pelas seguintes sequências de palavras binárias:
| Código em Assembly | Código em linguagem de máquina |
Mov #8, A |
01000011 11001000 01100001 |
Mov #9, B |
01000011 11001001 01100010 |
ADD A,B |
01010100 01100001 01100010 |
Houve um aumento significativo no nível de abstração, mas parte da dificuldade permanece, pois o programador, além de necessitar memorizar os mneumônicos, precisa conhecer a arquitetura do computador como forma de endereçamento dos registradores e memória, além de outros aspectos.
- LINGUAGENS DE 3ª GERAÇÃO (LINGUAGENS PROCEDURAIS) [nível-médio] são as, também, linguagens de alto nível, de aplicação geral, em que uma única instrução em uma linguagem próxima a do homem pode corresponder a mais de uma instrução em linguagem de máquina.
Caracterizam-se pelo suporte a variáveis do tipo simples (caractere, inteiro, real e lógico) e estruturados (matrizes, vetores, registros), comandos condicionais, comando de iteração e programação modular (funções e procedimentos), estando alinhadas à programação estruturada.
O processo de conversão para a linguagem de máquina ficou mais complexo e ficaram a cargo dos interpretadores e tradutores. As primeiras linguagens de 3ª geração que foram apresentadas ao mercado são: Fortran, BASIC, COBOL, C, PASCAL, dentre outras.
Esta geração de linguagens apresenta as seguintes propriedades em comum:
- Armazenar tipos de dados estaticamente: simples, estruturados e enumerados.
- Alocar memória dinamicamente, através de ponteiros, que são posições de memória cujo conteúdo é outra posição de memória.
- Disponibilizar: estruturas de controle sequencial, condicional, repetição e desvio incondicional.
- Permitir a programação modular, com uso de parâmetros.
- Operadores: relacionais, lógicos e aritméticos.
- Ênfase em simplicidade e eficiência.
- LINGUAGENS DE 4ª GERAÇÃO (LINGUAGENS APLICATIVAS) são, também, linguagens de alto nível, com aplicação e objetivos bem específicos.
Enquanto as linguagens de 3ª geração são procedurais, ou seja, especifica-se passo a passo a solução do problema, as de 4ª geração são não procedurais. O programador especifica o que deseja fazer e não como deve ser feito.
O melhor exemplo de linguagens de 4ª geração é a SQL (Structured Query Language), utilizada para consulta à manipulação de banco de dados. PostScript e MATLAB são outros dois exemplos de linguagens de 4ª geração.
- LINGUAGENS DE 5ª GERAÇÃO (VOLTADAS À INTELIGÊNCIA ARTIFICIAL), alto-nível, são linguagens declarativas e não algorítmicas. Exemplos: Lisp e Prolog. As linguagens de 5ª geração são usadas para desenvolvimento de sistemas especialistas (área da IA), de sistemas de reconhecimento de voz e machine learning.
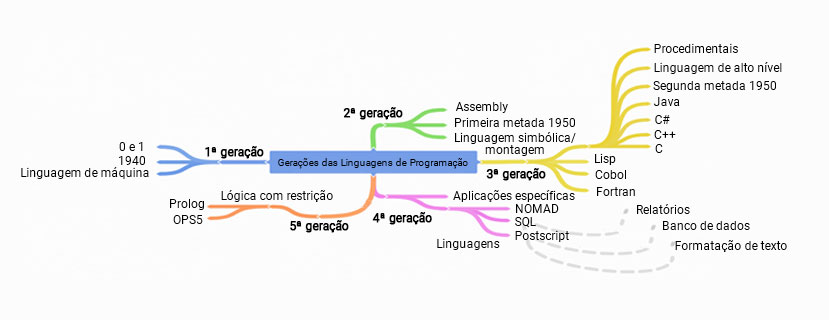
A imagem a seguir ilustra as características de cada geração.
Alguns autores classificam a 6ª geração, como uma evolução da 5ª, em que prevalecem as aplicações de redes neurais, uma outra vertente da Inteligência Artificial.
Resumindo:A abstração traz facilidades ao programador que cada vez menos precisa conhecer o ambiente onde a linguagem opera (composto por sistema operacional e hardware); Um comando em uma linguagem de alto nível faz mais que uma operação primária do hardware.
Considerando as diversas linguagens de programação existentes hoje no mercado, atendendo a propósito comuns, vamos destacar neste módulo os domínios da programação, que são seis:
- Aplicações científicas
- Aplicações comerciais
- Aplicações com Inteligência Artificial
- Programação de sistemas
- Programação para web
- Programação mobile
Na sequência, apresentaremos critérios que podem ser usados para avaliação de linguagens de programação, claro, dentro do mesmo domínio de programação.
O computador tem sido usado para diversos fins, na ciência, nas forças armadas, nas empresas públicas e privadas, pelos profissionais liberais, pelas pessoas em seus lazeres e onde mais possa ser aplicado. Seu uso vai desde controlar robôs que fazem a montagem de automóveis em suas linhas de montagem até jogos digitais. Em função desse uso adverso, surgiram linguagens de programação com diferentes objetivos. A seguir, discutiremos as principais áreas e as respectivas linguagens de programação em destaque.
APLICAÇÕES CIENTÍFICAS (MÁQUINAS DE CALCULAR COM ALTA PRECISÃO), o primeiro computador, o ENIAC, foi desenvolvido por 3 anos e ficou pronto no ano de 1946. Sua principal finalidade eram cálculos balísticos. Os computadores seguintes, nas décadas de 1940 e 1950, também focaram em cálculos científicos complexos.
As linguagens de programação nessa época eram a linguagem de máquina e Assembly. Na década de 1960 surgem as primeiras linguagens de programação de alto nível, com destaque para Fortran (iniciais de FORmula TRANslator) e posteriormente para ALGOL60. As principais características dessas linguagens eram:
- Estruturas de dados simples.
- Alto volume de cálculos com aritmética de ponto flutuante (precisão).
- Preocupação com a eficiência, pois sucederam a linguagem Assembly.
APLICAÇÕES COMERCIAIS, a segunda onda de aplicativos foi para suprir as demandas das empresas a partir de meados da década de 1950. Em 1960, surge a linguagem que seria o ícone das aplicações comerciais de computadores de grande porte, naquele momento, o COBOL. As linguagens de programação que apoiaram o crescimento das aplicações comerciais têm como características:
- Facilidade para produzir relatórios, fundamentais nos controles das operações contábeis, bancárias, estoque e financeiras (primeiros focos da época).
- Precisão com números decimais e ponto flutuante, para representar as altas cifras das grandes empresas, as primeiras a investirem nessas aplicações.
- Capacidade de especificar operações aritméticas comerciais.
Cabe destacar que as linguagens destinadas a aplicações comerciais ganham força com a microcomputação a partir dos anos 1980, levando as aplicações comerciais aos médios e pequenos empresários.
APLICAÇÕES COM INTELIGÊNCIA ARTIFICIAL, as linguagens que sustentam o desenvolvimento de aplicações apoiadas na Inteligência Artificial (IA) ganham força nos dias de hoje.
A grande ruptura no pensamento computacional é que as linguagens que apoiam a IA usam a computação simbólica e não numérica, como a maioria das linguagens da época. Em 1959, surge a linguagem Lisp, primeira linguagem projetada para apoio à computação simbólica, primeira referência da computação funcional. Prolog, criada em 1977, foi a primeira linguagem para apoio da computação lógica, essência dos sistemas especialistas (sistemas que usam IA para simular o comportamento humano).
PROGRAMAÇÃO DE SISTEMAS, a programação de sistemas cabe a linguagens de programação que tenham comandos e estruturas para acessar, diretamente, o hardware. Tais linguagens são usadas para desenvolver softwares básicos, como sistemas operacionais, tradutores e interpretadores de linguagens de programação. Antes de surgir a linguagem C, usada para desenvolver o sistema operacional Linux, Assembly era a linguagem usada para esse fim. A linguagem C++ também é usada com essa finalidade.
PROGRAMAÇÃO PARA WEB, com o crescimento da internet e tecnologias adjacentes, o uso dos sistemas se desloca do ambiente desktop (domínio dos anos 1980 e 1990) para o ambiente Web.
No contexto de programação para Web, temos 2 diferentes ambientes de desenvolvimento: a camada de apresentação, que roda no navegador (lado cliente) e a camada de lógica do negócio, que roda nos servidores web (lado servidor), juntamente com a camada de persistência, considerando o modelo de desenvolvimento em 3 camadas (apresentação, lógica do negócio e persistência de dados).
Para a camada de apresentação, usa-se as linguagens HTML (linguagem de marcação) e CSS (usada em conjunto com HTML para definir a apresentação da página web), além de JavaScript (programação de scripts), no lado cliente (navegadores).
Para o desenvolvimento das camadas de lógica do negócio, as principais LP são: C#, PHP, ASP, .NET, Java, Ruby e Python.
PROGRAMAÇÃO MOBILE, considerando que hoje em dia, grande parte da população, no Brasil e no Mundo, tem acesso à internet pelo celular, cresceu vertiginosamente a quantidade de apps (aplicativos) para uso de aplicações via celular. Os apps, na verdade, são interfaces que rodam no lado cliente.
As principais (não todas) linguagens que apoiam o desenvolvimento de apps para o mundo mobile, oficialmente indicadas por seus fabricantes, são:
- Android: Java e Kotlin.
- iOS: Swift (oficial da Apple) e Objective-C (código nativo para iOS).
- Windows: C#, Visual Basic (VB), C++, HTML, CSS, JavaScript e Java.
O desenvolvimento de APP para iOS é baseado numa IDE chamada Xcode que permite o desenvolvimento de APP em várias linguagens, como: C, C++, Java e Python, mas oficialmente orienta o Swift e Objective-C.
A Google, por sua vez, tem por base o Android SDK, orienta a usar as linguagens Kotlin, Java e C++, mas as linguagens Python, Shell script, Basic4Android, LiveCode (para iOS e Windows também), App Inventor (não necessita conhecer programação) e Unity (motor para games) e GO, também são usadas para desenvolver app para Android.
No contexto de desenvolvimento de APP para Windows, foi lançado no Windows 8.1 e atualizado para atender também ao Windows 10, o App Studio, que permite a qualquer pessoa criar em poucos passos um app Windows e publicá-lo na loja.
Importante destacar que hoje existem plataformas de desenvolvimento mobile conectadas a nuvem que fomentam o desenvolvimento de apps nativos para iOS, Android e Windows.
Segundo Sebesta (2018) são quatro grandes critérios para avaliação das linguagens de programação, dentro de um mesmo domínio de programação. Cada critério é influenciado por algumas características da linguagem.
Legibilidade: Um dos critérios mais relevantes é a “facilidade com que os programas podem ser lidos e entendidos” pelas pessoas que não necessariamente participaram do desenvolvimento.
Facilidade de escrita: O quão facilmente uma linguagem pode ser usada para desenvolver programas para o domínio do problema escolhido.
Confiabilidade: Um programa é dito confiável se ele se comporta conforme a sua especificação, repetidas vezes.
Custo: O custo final de uma linguagem de programação é em função de muitas de suas propriedades e características.
A tabela a seguir exibe as características da linguagem que influenciam cada um dos três principais fatores de avaliação de linguagens.
| Critérios | |||
| Características | Legibilidade | Facilidade escrita | Confiabilidade |
| Simplicidade | xxxxxxxxxxxx | xxxxxxxxxxxx | xxxxxxxxxxxx |
| Ortogonalidade | xxxxxxxxxxxxxx | xxxxxxxxxxxxxx | xxxxxxxxxxxxxx |
| Estruturas de controle | xxxxxxxxxxxxxxxxx | xxxxxxxxxxxxxxxxx | xxxxxxxxxxxxxxxxx |
| Tipos de dados | xxxxxxxxxxxxxx | xxxxxxxxxxxxxx | xxxxxxxxxxxxxx |
| Projeto de sintaxe | xxxxxxxxxxxxxxxxxx | xxxxxxxxxxxxxxxxxx | xxxxxxxxxxxxxxxxxx |
| Suporte para abstração | xxxxxxxxxxxxxxxxxx | xxxxxxxxxxxxxxxxxx | |
| Expressividade | xxxxxxxxxxxxxxxxxx | xxxxxxxxxxxxxxxxxx | |
| Verificação de tipos | xxxxxxxxxxxxxxxxxx | ||
| Tratamento de exceções | xxxxxxxxxxxxxxxxxx | ||
| Aliasing | xxxxxxxxxxxxxxxxxx |
Características x Critérios de Avaliação de LPs
Legibilidade: Um dos critérios mais relevantes para avaliar uma linguagem de programação diz respeito à capacidade com que os programas podem ser lidos e entendidos pela sintaxe e construção da linguagem, sem considerar as possíveis influências da má programação.
As características que influenciam a legibilidade de uma linguagem de programação são:
SIMPLICIDADE: Quanto mais simples for uma linguagem, melhor será a legibilidade do código por ela produzido. Uma linguagem com número elevado de construções básicas é mais difícil de ser aprendida do que uma que tenha poucas. Tende a ser subutilizada.
Uma segunda característica que afeta negativamente a legibilidade é a multiplicidade de recursos. Por exemplo, em Python, o programador pode incrementar uma variável, de duas formas distintas:
cont = cont + 1cont += 1
Nas linguagens C e Java, ainda podemos usar para incrementar variáveis as seguintes estruturas: ++cont e cont++.
Muita simplicidade pode tornar menos legíveis os códigos escritos. Na linguagem Assembly, a maioria das sentenças são simples, porém não são altamente legíveis devido à ausência de estruturas de controle.
Uma terceira característica que afeta negativamente a legibilidade é a sobrecarga de operadores, como por exemplo o +, usado para somar inteiros, reais, concatenar cadeias de caracteres (strings), somar vetores (Arrays), dentre outras construções permitidas pela linguagem.
A ortogonalidade de uma linguagem refere-se a um conjunto relativamente pequeno de construções primitivas que pode ser combinado em um número, também, pequeno de maneiras para construir as estruturas de controle e de dados de uma linguagem de programação.
Em outras palavras: possibilidade de combinar, entre si, sem restrições, as construções básicas da linguagem para construir estruturas de dados e de controle.
- Boa ortogonalidade: Permitir, por exemplo, que haja um vetor, cujos elementos sejam do tipo registro (estrutura heterogênea).
- Má ortogonalidade: Não permitir que um vetor seja passado como argumento para uma rotina (procedimento ou função). Ou que uma função não possa retornar um vetor. Uma linguagem ortogonal tende a ser mais fácil de aprender e tem menos exceções.
A falta de ortogonalidade leva a muitas exceções às regras da linguagem e ao excesso, o contrário (menos exceções às regras). Menos exceções implicam um maior grau de regularidade no projeto da linguagem, tornando-a mais fácil de ler, entender e aprender.
INSTRUÇÕES DE CONTROLE: Instruções como Goto (desvio incondicional) limitam a legibilidade dos programas, pois essa instrução pode levar o controle do código a qualquer ponto do programa, limitando o entendimento e, consequentemente, a legibilidade do código escrito na linguagem. As linguagens modernas não implementam desvio incondicional, assim sendo, o projeto de estruturas de controle é menos relevante na legibilidade do que anos atrás, quando surgiram as primeiras linguagens de alto nível.
A facilidade oferecida pela linguagem para definir tipos e estruturas de dados é outra propriedade que aumenta a legibilidade do código escrito. Por exemplo, uma linguagem que permita definir registros e vetores, mas não permite que um vetor tenha registros como seus elementos, terá a legibilidade afetada.
A linguagem C não possui o tipo de dado lógico ou booleano. Muitas vezes, usa-se variáveis inteiras, permitindo apenas que receba os valores 0 e 1 para conteúdo, simulando o tipo booleano. Por exemplo, para localizar um elemento em uma das posições de um vetor, usa-se uma variável lógica se a linguagem permitir e, assim, teríamos a instrução achou=false em determinado trecho de código. Em outra linguagem que não permita o tipo de dado lógico, a instrução poderia ser achou=0, em que achou seria uma variável inteira. Qual das duas sentenças é mais clara a quem lê o código? A primeira, não é? achou=false.
A sintaxe tem efeito sobre a legibilidade. Um exemplo é a restrição do tamanho (quantidade de caracteres) para um identificador (tipo, variável, constante, rotina – procedimento e função), impedindo que recebam nomes significativos sobre sua utilidade. Na linguagem Fortran, o nome do identificador pode ser até 6 caracteres.
Outra propriedade de sintaxe que afeta a legibilidade é o uso de palavras reservadas da linguagem. Por exemplo, em Pascal, os blocos de instrução são iniciados e encerrados com BEGIN-END, respectivamente. A linguagem C usa chaves para iniciar e encerrar blocos de instruções. Já a linguagem Python usa a endentação obrigatória para marcar blocos de comandos, aumentando a legibilidade, naturalmente.
A facilidade de escrita (redigibilidade) é a medida do quão fácil a linguagem permite criar programas para um domínio da aplicação.
A maioria das características que afeta a legibilidade também afeta a facilidade de escrita, pois se a escrita do código não flui, haverá dificuldade para quem for ler o código.
As características que influenciam na facilidade de escrita são:
SIMPLICIDADE E ORTOGONALIDADE: Quanto mais simples e ortogonal for a linguagem, melhor sua facilidade para escrever programas. O ideal são linguagens com poucas construções primitivas.
Imagina que uma linguagem de programação possui grande número de construções. Alguns programadores podem não usar todas, deixando de lado, eventualmente, as mais eficientes e elegantes.
Uma linguagem de programação com boa expressividade contribui para o aumento da facilidade de escrita dos códigos.
- Assembly: Baixa expressividade.
- Pascal e C, boa expressividade: Ricas estruturas de controle. Exemplo: o comando
FORmais adequado queWHILEeREPEATpara representar lações com número fixo de vezes. Da mesma forma que o C, em que oFORé mais indicado que oWHILEeDO-WHILE. Na linguagem Python, ocorre o mesmo entre os comandosFOReWHILE. - Na linguagem C, temos construções diversas para incremento de variável:
i++é mais simples e conveniente de usar do quei=i+1, sendoi, uma variável inteira. Uma linguagem expressiva possibilita escrever linhas de código de uma forma mais conveniente ao invés de deselegante.
SUPORTE PARA A ABSTRAÇÃO: O grau de abstração em uma linguagem é uma propriedade fundamental para aumentar a facilidade de escrita. Abstração pode ser de:
- Processos, como o conceito de subprograma.
- Dados, como uma árvore ou lista simplesmente encadeada.
Confiabilidade: Dizemos que um programa é confiável se ele se comportar conforme sua especificação, sob todas as condições, todas as vezes em que for executado.
Abaixo, alguns recursos das linguagens que exercem efeito sobre a confiabilidade de programas.
VERIFICAÇÃO DE TIPOS: Significa verificar, em tempo de compilação ou execução, se existem erros de tipo. Por exemplo, atribuir um valor booleano a uma variável do tipo inteira, vai resultar em erro. As linguagens fortemente tipadas, em tempo de compilação, como Python e Java, tendem a ser mais confiáveis, pois apenas valores restritos aos tipos de dados declarados poderão ser atribuídos e diminuem os erros em tempo de execução. Linguagens, como C, em que não é verificado se o tipo de dado do argumento é compatível com o parâmetro, em tempo de compilação, podem gerar erros durante a execução, afetando a confiabilidade. A verificação de tipos em tempo de compilação é desejável, já em tempo de execução é dispendiosa (mais lenta e requer mais memória), e mais flexível (menos tipada).
O tratamento de exceção em uma linguagem de programação garante a correta execução, aumentando a confiabilidade. As linguagens Python, C++ e Java possuem boa capacidade de tratar exceções, ao contrário da linguagem C. A linguagem deve permitir a identificação de eventos indesejáveis (estouro de memória, busca de elemento inexistente, overflow etc.) e especificar respostas adequadas a cada evento. O comportamento do programa torna-se previsível com a possibilidade de tratamento das exceções, o que tende a aumentar a confiabilidade do código escrito na linguagem de programação.
Aliasing (APELIDOS) é o fato de ter dois ou mais nomes, referenciando a mesma célula de memória, o que é um recurso perigoso e afeta a confiabilidade. Restringir Aliasing é prover confiabilidade aos programas.
Ambos influenciam a confiabilidade. A legibilidade afeta tanto na fase de codificação como na fase de manutenção. Programas de difícil leitura são difíceis de serem escritos também.
Uma linguagem com boa legibilidade e facilidade de escrita gera códigos claros, que tendem a aumentar a confiabilidade.
O custo de uma linguagem de programação varia em função das seguintes despesas: de treinamento, de escrita do programa, do compilador, de execução do programa, de implementação da linguagem e o de manutenção do código.
| Custo de | Características |
| Treinamento | Custo de Treinamento para programadores varia em função da expertise do programador, simplicidade e ortogonalidade da linguagem; F (simplicidade de escrita, ortogonalidade, experiência do programador). |
| Escrever programa | Custo para escrever programas na linguagem varia em função da facilidade de escrita. F(Facilidade de escrita). |
| Compilar o programa | Esse custo varia em função do custo de aquisição do compilador, hoje minimizado, em linguagens open source, como é o caso do Python. F (custo de aquisição do compilador). |
| Executar o programa | Custo para executar programas, varia em função do projeto da linguagem. F (Projeto da linguagem). |
| Implementar a linguagem | A popularidade da LP vai depender de um econômico sistema de implementação. Por exemplo, Python e Java possuem compiladores e interpretadores gratuitos. |
| Confiabilidade | O custo da má confiabilidade: se um sistema crítico falhar, o custo será elevado. Exemplos: sistema de controle de consumo de água e sistemas de usina nuclear. |
| Manutenção | Custo de manutenção: depende de vários fatores, mas principalmente da legibilidade, já que a tendência é que a manutenção seja dada por pessoas que não participaram do desenvolvimento do software. |
Os custos em treinamento e de escrever o programa podem ser minimizados se a linguagem oferecer bom ambiente de programação.
Python é uma linguagem com alta legibilidade, facilidade de escrita, além de confiável. Seu custo não é elevado, pois além de ser open source, é fácil de aprender.
Warning
ATENÇÃO! Existem outros critérios, como por exemplo a portabilidade ou a capacidade que os programas têm de rodarem em ambientes diferentes (sistema operacional e hardware), o que é altamente desejável. A reusabilidade, ou seja, o quanto um código pode ser reutilizado em outros programas ou sistemas aumenta o nível de produtividade da linguagem. Além da facilidade de aprendizado, que é fortemente afetada pela legibilidade e facilidade de escrita.
Como funcionam C++, Java e Python? O diagrama mostra como a compilação e a execução funcionam:
Linguagens compiladas são compiladas em código de máquina pelo compilador. O código de máquina pode ser executado diretamente pela CPU posteriormente. Exemplos: C, C++, Go.
Uma linguagem bytecode como Java compila o código-fonte em bytecode primeiro, depois a JVM executa o programa. Às vezes, o compilador JIT (Just-In-Time) compila o código-fonte em código de máquina para acelerar a execução. Exemplos: Java, C#
Linguagens interpretadas não são compiladas. Eles são interpretados pelo intérprete durante a execução. Exemplos: Python, Javascript, Ruby
Linguagens compiladas em geral rodam mais rápido que linguagens interpretadas.
A palavra é sua: qual tipo de linguagem você prefere?
O agrupamento por paradigmas é outra forma de classificar as linguagens de programação. Um paradigma agrupa linguagens com características semelhantes que surgiram em uma mesma época.
A imagem a seguir ilustra os cinco paradigmas nos quais as linguagens de programação são classificadas. Esses paradigmas são agrupados em Imperativos e Declarativos, de acordo com a forma com que os programas são estruturados e descritos.
O paradigma imperativo agrega três paradigmas: estruturado, orientado a objeto e concorrente, os quais possuem em comum o fato de especificarem passo a passo o que deve ser feito para a solução do problema. As linguagens do paradigma imperativo são dependentes da arquitetura do computador, pois especificam em seus programas como a computação é realizada.
Vamos explicar as características de cada um dos paradigmas do subgrupo Imperativo.
Paradigma estruturado caracteriza as principais linguagens de programação da década de 1970 e 1980 que seguiram os princípios da programação estruturada:
- Não usar desvios incondicionais (Goto, característico de linguagens como BASIC e versões iniciais do COBOL).
- Desenvolver programas por refinamentos sucessivos (metodologia top down), motivando o desenvolvimento de rotinas (procedimentos e funções) e a visão do programa partindo do geral para o particular, ou seja, o programa vai sendo refinado à medida que se conhece melhor o problema e seus detalhes.
- Desenvolver programas usando três tipos de estruturas: sequenciais, condicionais e repetição.
- Visando eficiência, o paradigma estruturado baseia-se nos princípios da arquitetura de Von Neumann, onde:
- Programas e dados residem, na memória (durante a execução).
- Instruções e dados trafegam da memória para CPU e vice-versa.
- Resultados das operações trafegam da CPU para a memória.
As linguagens Pascal e C caracterizam bem esse paradigma. A linguagem Python, multiparadigma, tem o estilo básico do paradigma estruturado.
Paradigma orientado a objetos, com o crescimento do tamanho do código e complexidade dos programas, o paradigma estruturado começou a apresentar limitações nos sistemas que passaram a ter dificuldade de manutenção e reuso de programas e rotinas padronizadas.
A orientação a objetos surge como solução a esses problemas, permitindo, através de propriedades como abstração, encapsulamento, herança e polimorfismo, maior organização, reaproveitamento e extensibilidade de código e, consequentemente, programas mais fáceis de serem escritos e mantidos.
O principal foco desse paradigma foi possibilitar o desenvolvimento mais rápido e confiável.
As classes são abstrações que definem uma estrutura que encapsula dados (chamados de atributos) e um conjunto de operações possíveis de serem usados, chamados métodos. Os objetos são instâncias das classes.
Exemplo: Por exemplo, a classe ALUNO encapsula um conjunto de dados que os identifiquem: matrícula, nome, endereço (rua, número, complemento, bairro, estado e CEP) e um conjunto de métodos: Incluir Aluno, Matricular Aluno, Cancelar Matrícula, dentre outros.
O paradigma orientado a objetos (OOP - POO), por sua vez, usa os conceitos do paradigma estruturado na especificação dos comandos de métodos. Por isso, é considerado uma evolução do paradigma estruturado.
Atenção: Python, Smalltalk, C++, Java, Delphi (oriundo do Object Pascal) são linguagens que caracterizam o paradigma orientado a objetos. Python é orientado a objeto, pois tudo em Python é objeto, permitindo a declaração de classes encapsuladas, além de possibilitar herança e polimorfismo.
Paradigma concorrente caracterizado quando processos executam simultaneamente e concorrem aos recursos de hardware (processadores, discos e outros periféricos), características cada vez mais usuais em sistemas de informação.
O paradigma concorrente pode valer-se de apenas um processador ou vários.
- Processador: Os processos concorrem ao uso do processador e recursos.
- Vários processadores: Estamos caracterizando o paralelismo na medida em que podem executar em diferentes processadores (e de fato, ao mesmo tempo), os quais podem estar em uma mesma máquina ou distribuídos em mais de um computador.
Ada e Java são as linguagens que melhor caracterizam esse paradigma, possibilitando suporte à concorrência.
Tip
Ao contrário de Go, Python não foi originalmente projetada com foco em programação concorrente, muito menos paralela.
O modo tradicional de programar concorrência em Python -- threads -- é limitado no interpretador padrão (CPython) por uma trava global (a GIL), que impede a execução paralela de threads escritas em Python. Isso significa que threads em Python são úteis apenas em aplicações I/O bound (Aplicações I/O bound são aquelas em que há predomínio de ações de entrada e saída de dados.) – em que o gargalo está no I/O (entrada e saída), como é o caso de aplicações na Internet.
Paradigma funcional abrange linguagens que operam tão somente funções que recebem um conjunto de valores e retornam um valor. O resultado que a função retorna é a solução do problema (foca o processo de resolução de problemas).
O programa resume-se em chamadas de funções, que por sua vez podem usar outras funções. Uma função pode invocar outra, ou o resultado de uma função pode ser argumento para outra função. Usa-se também chamadas recursivas de funções.
Naturalmente, esse paradigma gera programas menores (pouco código).
Linguagens típicas desse paradigma são: LISP, HASKELL e ML.
LISP é a LP funcional mais usada, especialmente em programas que usem os conceitos de Inteligência Artificial (sistemas especialistas, processamento de linguagem natural e representação do conhecimento), devido à facilidade de interpretação recursiva.
Exemplo: O código abaixo implementa em Python uma função que calcula quantos números inteiros existem de 0 a n.
def conta_numeros(n):
p = 0
for num in range(n+1):
if num%2 == 0:
p += 1
return pAbaixo, o mesmo código usando o conceito de função recursiva. Repare que a função de nome conta_numeros chama ela mesma em seu código (isso é a recursão).
def conta_numeros(n):
if n == 0: return 1 # 0 é par
elif n%2 == 0: return 1 + conta_numeros(n-1)
else: return conta_numeros(n-1)Atenção: Python não é uma linguagem funcional nativa, seria exagerado afirmar isso, porém sofreu influência desse paradigma ao permitir: recursividade, uso de funções anônimas, com a função lambda, dentre outros recursos, além, claro, de ser uma linguagem com enorme biblioteca de funções.
Um programa lógico expressa a solução da maneira como o ser humano raciocina sobre o problema: baseado em fatos, derivam-se conclusões e novos fatos.
Quando um novo questionamento é feito, através de um mecanismo inteligente de inferência, deduz novos fatos a partir dos existentes.
A execução dos programas escritos em linguagens de programação lógica segue, portanto, um mecanismo de dedução automática (máquina de inferência), sendo Prolog a linguagem do paradigma lógico mais conhecida.
O paradigma lógico é usado no desenvolvimento de linguagens de acesso a banco de dados, sistemas especialistas (IA), tutores inteligentes etc.
Python não tem características para implementar programas que atendam ao paradigma lógico.
Todo programa, a menos que seja escrito em linguagem de máquina, o que hoje em dia está totalmente fora dos propósitos, precisará ser convertido para linguagem de máquina antes de ser executado.
Essa conversão precisa de um programa que receba o código-fonte escrito na linguagem e gere o respectivo código em linguagem de máquina. Esse programa, que fará a tradução do código-fonte em linguagem de máquina, é que vai determinar como os programas são implementados e como vão executar.
Existem duas formas de realizar essa conversão: tradução e interpretação. É fundamental que se saiba e se entenda qual o processo de conversão usado na respectiva linguagem de programação.
Você já parou para pensar como um programa escrito em uma linguagem de programação qualquer é convertido para um conjunto de comandos que podem ser executados por um computador?
Uma CPU somente consegue manipular 0 e 1, ou seja bits, de forma que, para um programa ser executado, ele deve passar por um processo de transformação de suas instruções, escritas em alguma linguagem de alto nível, para um conjunto de instruções em linguagem de máquina, que é aquela que efetivamente o processador consegue executar. Este processo de transformações é, de uma forma geral, denominado tradução, podendo ser realizado de várias formas.
Neste tema, iremos apresentar as diversas formas de tradução e nos deteremos mais especificamente na compilação. Em sistemas operacionais, o compilador (compiler) é um programa de computador que transforma o código-fonte escrito em uma linguagem compilada em um programa semanticamente equivalente em código objeto.
Há duas formas diferentes de transformar um programa de uma linguagem de programação de alto nível em linguagem de máquina:
-
COMPILAÇÃO - o source program é traduzido uma vez (no entanto, este ato deve ser repetido sempre que modificar o source code) obtendo um ficheiro (por exemplo, um
ficheiro.exese o código se destinar a ser executado no MS Windows) contendo o machine code; agora pode distribuir o ficheiro por todo o mundo; o programa que executa esta tradução chama-se compilador ou tradutor (compiler); -
INTERPRETAÇÃO - você (ou qualquer utilizador do código) pode traduzir o source program cada vez que este tem de ser executado; o programa que executa este tipo de transformação chama-se intérprete ou interpretador, pois interpreta o código cada vez que se pretende executá-lo; também significa que não pode simplesmente distribuir o source code tal como está, porque o utilizador final também precisa do intérprete para o executar.
Aprenda mais: O interpretador converte para código de máquina, em tempo de execução. O compilador traduz o programa inteiro em código de máquina e o executa, gerando um arquivo que pode ser executado. O compilador gera um relatório de erros e o interpretador interrompe o processo na medida em que localiza um erro.
Devido a algumas razões muito fundamentais, uma linguagem de programação particular de alto nível foi concebida para se enquadrar numa destas duas categorias.
Há muito poucas linguagens que possam ser compiladas e interpretadas. Normalmente, uma linguagem de programação é projetada com este fator na mente dos seus construtores - será ela compilada ou interpretada?
Vamos assumir mais uma vez que escreveu um programa. Agora, existe como um ficheiro de computador (computer file): um programa de computador é na realidade um pedaço de texto, por isso o source code é normalmente colocado em ficheiros de texto (text files).
Nota: tem de ser texto puro, sem quaisquer decorações como diferentes fontes, cores, imagens embutidas ou outros suportes. Agora tem de invocar o intérprete e deixá-lo ler o seu source file.
O intérprete lê o source code de uma forma que é comum na cultura ocidental: de cima para baixo e da esquerda para a direita, porém há algumas exceções.
Em primeiro lugar, o intérprete verifica se todas as linhas subsequentes estão corretas (utilizando os quatro aspetos abordados anteriormente). Se o compilador encontrar um erro, termina o seu trabalho imediatamente. O único resultado, neste caso, é uma mensagem de erro.
O intérprete informá-lo-á onde se encontra o erro e o que o causou. No entanto, estas mensagens podem ser enganadoras, uma vez que o intérprete não é capaz de seguir exatamente as suas intenções, e pode detectar erros a alguma distância das suas verdadeiras causas.
Por exemplo, se tentar utilizar uma entidade com um nome desconhecido, causará um erro, mas o erro será descoberto no local onde tenta utilizar a entidade, e não onde o nome da nova entidade foi introduzido.

Por outras palavras, a razão real está normalmente localizada um pouco mais cedo no código, por exemplo, no local onde teve de informar o intérprete de que ia utilizar a entidade do nome.
Se a linha parecer boa, o intérprete tenta executá-la (nota: cada linha é normalmente executada separadamente, pelo que o trio "read-check-execute" pode ser repetido muitas vezes - mais vezes do que o número real de linhas no source file, uma vez que algumas partes do código podem ser executadas mais de uma vez).
É também possível que uma parte significativa do código possa ser executada com sucesso antes de o intérprete encontrar um erro. Este é um comportamento normal neste modelo de execução.
Pode perguntar agora: o que é melhor? O modelo "compilador" ou o modelo "intérprete"? Não há uma resposta óbvia. Se houvesse, um destes modelos já teria deixado de existir há muito tempo. Ambos têm as suas vantagens e as suas desvantagens.
O intérprete informá-lo-á onde se encontra o erro e o que o causou. No entanto, estas mensagens podem ser enganadoras, uma vez que o intérprete não é capaz de seguir exatamente as suas intenções, e pode detectar erros a alguma distância das suas verdadeiras causas.
Por exemplo, se tentar utilizar uma entidade com um nome desconhecido, causará um erro, mas o erro será descoberto no local onde tenta utilizar a entidade, e não onde o nome da nova entidade foi introduzido.
Por outras palavras, a razão real está normalmente localizada um pouco mais cedo no código, por exemplo, no local onde teve de informar o intérprete de que ia utilizar a entidade do nome.
Se a linha parecer boa, o intérprete tenta executá-la (nota: cada linha é normalmente executada separadamente, pelo que o trio "read-check-execute" pode ser repetido muitas vezes - mais vezes do que o número real de linhas no source file, uma vez que algumas partes do código podem ser executadas mais de uma vez).
É também possível que uma parte significativa do código possa ser executada com sucesso antes de o intérprete encontrar um erro. Este é um comportamento normal neste modelo de execução.
Pode perguntar agora: o que é melhor? O modelo "compilador" ou o modelo "intérprete"? Não há uma resposta óbvia. Se houvesse, um destes modelos já teria deixado de existir há muito tempo. Ambos têm as suas vantagens e as suas desvantagens.
| Vantagens | |
|---|---|
| COMPILAÇÃO | INTERPRETAÇÃO |
| A execução do código traduzido é geralmente mais rápida; | |
| Apenas o utilizador tem de ter o compilador - o end-user (utilizador final) pode usar o código sem ele; | Pode executar o código assim que o concluir - não há fases adicionais de tradução; |
| O código traduzido é armazenado utilizando linguagem de máquina - como é muito difícil de entender, as suas próprias invenções e truques de programação provavelmente permanecerão segredo. | o código é armazenado usando linguagem de programação, não de máquina - isto significa que pode ser executado em computadores utilizando diferentes linguagens de máquina; não se compila o código separadamente para cada arquitetura diferente. |
| Desvantagens | |
|---|---|
| COMPILAÇÃO | INTERPRETAÇÃO |
| A compilação em si pode ser um processo muito demorado - pode não ser capaz de executar o seu código imediatamente após qualquer alteração; | Não espere que a interpretação aumente o seu código para alta velocidade - o seu código irá partilhar o poder do computador com o intérprete, pelo que não pode ser realmente rápido; |
| Tem de ter tantos compiladores quanto plataformas de hardware em que queira que o seu código seja executado. | Tanto você como o end-user têm de ter o intérprete para executar o seu código. |
Hoje em dia, o desenvolvimento de sistemas se baseia em vários e diferentes paradigmas para a resolução de problemas e implementação das regras de negócio, todos eles possuem funcionalidades e recursos diferentes entre si que atuam para um propósito específico, e a escolha de uma linguagem de programação para atender a essas tarefas é muito importante, a única semelhança entre eles é que ambos fazem uso do processamento da máquina pela CPU e a alocação de dados na memória do computador (RAM, Cache ou HD), tais como os listados a seguir:
Máquina: O paradigma de linguagem de máquina se refere a um nível muito baixo de linguagem de programação, onde as instruções são escritas em códigos binários (0s e 1s) compreendidos diretamente pelo hardware do computador, em estruturas condicionais sendo 0 representado como falso e 1 representado como verdadeiro, na maioria dos casos. É a linguagem na qual os processadores entendem e executam instruções. As linguagens de máquina são específicas para cada tipo de processador (CPU), e cada instrução corresponde a uma operação específica que o processador pode realizar, como carregar dados da memória, realizar operações aritméticas, armazenar resultados e controlar o fluxo do programa. Embora seja a linguagem fundamental para a execução de programas, a programação diretamente em linguagem de máquina é extremamente complexa e difícil de ser compreendida e escrita por humanos. Por isso, surgiram linguagens de programação de nível mais alto, como C, Python, Java, entre outras, que oferecem abstrações mais amigáveis e próximas da linguagem humana, sendo traduzidas para linguagem de máquina por compiladores ou interpretadores antes da execução no hardware do computador.
Montagem (Assembler): O paradigma de montagem, também conhecido como linguagem de montagem ou assembler, está relacionado à programação de baixo nível. É uma linguagem de programação de nível intermediário entre linguagem de máquina e linguagens de alto nível. A linguagem de montagem é uma representação simbólica da linguagem de máquina. Ela usa símbolos, chamados mnemônicos, para representar as instruções do processador e os endereços de memória. Cada instrução em linguagem de montagem corresponde diretamente a uma instrução em linguagem de máquina. Os programas escritos em linguagem de montagem são chamados de códigos-fonte e precisam ser traduzidos para linguagem de máquina por meio de um programa chamado "montador" ou "assembler". Esse processo de tradução é conhecido como montagem e gera um arquivo executável que pode ser executado diretamente pelo hardware. Embora a linguagem de montagem permita um nível maior de abstração em comparação com a linguagem de máquina, ela ainda é bastante específica para a arquitetura do processador e exige um conhecimento detalhado da estrutura do hardware. Por esse motivo, é menos utilizada hoje em dia, exceto em situações específicas, como otimizações de desempenho ou desenvolvimento de sistemas embarcados. A linguagem de montagem é frequentemente chamada de linguagem Assembly. Ela utiliza mnemônicos e representações simbólicas para facilitar a programação de baixo nível, oferecendo uma forma mais legível e compreensível para os programadores em comparação com a linguagem de máquina, que é baseada em códigos binários.
Obs: Em todos os paradigmas de linguagens de programação de alto-nível ou nível-médio abaixo podem ser implementadas estrutura de dados e algoritmos, exceto em linguagens de baixo-nível como: linguagem de máquina e linguagem de montagem. Assim, como todos eles fazem uso da UML - Unified Modeling Language, Modelagem de dados, Módulos e importação de bibliotecas com gerenciadores de pacotes e gerenciadores de versões, Implementação com Banco de dados, design patterns - padrão de projetos, arquitetura de software, arquitetura de sistemas, metodologias ágeis e DevOps.
Lógico: Voltado ao desenvolvimento de problemas de lógica e usado em sistemas de inteligência computacional. O paradigma de programação lógico é um estilo de desenvolvimento de software baseado na lógica formal. Ele se concentra na definição de regras, fatos e relações lógicas para resolver problemas. A linguagem mais conhecida e utilizada nesse paradigma é a Prolog. Em Prolog e em outros sistemas de programação lógica, os programas são expressos em termos de regras de inferência lógica, onde o desenvolvedor especifica as relações entre os dados em vez de fornecer uma sequência de comandos ou algoritmos. No paradigma lógico, você descreve o que deve ser feito, e o sistema de execução (interpretador ou compilador) se encarrega de encontrar as soluções para o problema com base nessas regras lógicas. O mecanismo de inferência lógica resolve consultas, unificando fatos e regras para satisfazer as condições definidas.
Declarativo: Diferentemente do paradigma imperativo, no declarativo o programador diz o que o programa deve fazer (qual a tarefa), ao invés de descrever como o programa deve fazer. O programador declara, de forma abstrata, a solução do problema. Essas linguagens não são dependentes de determinada arquitetura de computador. As variáveis são incógnitas, tal qual na Matemática e não células de memória. O paradigma declarativo agrega os paradigmas funcional e lógico. A programação declarativa enfatiza a expressão de lógica e funcionalidades sem descrever explicitamente o fluxo de controle. Programação funcional é uma forma popular de programação declarativa.
Imperativo (Procedural/Estruturado): Geralmente, é a primeiro paradigma de linguagens de programação de alto-nível a ser estudado em lógica de programação e algoritmos com uma linguagem de programação ou pseudo-código (Portugol), onde segue as sequências de comandos ordenados segundo uma lógica. Na ciência da computação, programação imperativa é um paradigma de programação de software que descreve a computação como ações, enunciados ou comandos que mudam o estado (variáveis) de um programa. Semelhante ao comportamento imperativo das linguagens naturais que expressam ordens, programas imperativos são uma sequência de comandos para o computador executar. O termo é frequentemente usado em contraste com a programação declarativa, que se concentra no que o programa deve realizar sem especificar todos os detalhes de como o programa deve alcançar o resultado. Linguagens de programação que baseiam no modo imperativo são: Ada, ALGOL, Basic, C, PHP, Java, Cobol, Fortran, Pascal, Python, Lua, Mathematica, JavaScript e etc. O nome do paradigma, Imperativo, está ligado ao tempo verbal imperativo: "ação verbal é expressa como ordem, conselho, pedido" no presente, onde o programador diz ao computador: faça isso, depois isso, depois aquilo. Este paradigma de programação se destaca pela simplicidade, uma vez que todo ser humano, ao se programar, o faz imperativamente, baseado na ideia de ações e estados, quase como um programa de computador. Imperativa Programação Imperativa descreve uma sequência de etapas que alteram o estado do programa. Linguagens como C, C++, Java, Python (até certo ponto) e muitas outras suportam estilos de programação imperativos.
Orientado a Objetos (OOP): Geralmente, é o segundo paradigma de linguagens de programação de alto-nível que é estudado, onde define um conjunto de classes para dividir o problema e realiza a interação entre as diferentes classes para também resolver o problema como um todo. O paradigma Orientado a Objetos (OO) é um estilo de programação que se baseia no conceito de "objetos", nos quais os dados e as operações que podem ser realizadas com esses dados estão encapsulados juntos. Ele se concentra na modelagem do mundo real, representando entidades como objetos que possuem características (atributos) e comportamentos (métodos) como também os argumentos que são os valores passados para um método quando ele é invocado, enquanto os "parâmetros" são as variáveis que recebem esses valores dentro da definição do método. Existem quatro pilares principais de princípios do paradigma Orientado a Objetos: Abstração, Encapsulamento, Herança e Polimorfismo. Assim como também outros pontos muito importantes são: Associação, Composição, Delegação, Interface, Acoplamento e coesão, Mensagens, Tratamento de exceções (Exceptions), Constates e Self e Parent, Referência e Clonagem, Getters e Setters, Estado e Comportamento, Serialização e Desserialização, Políticas e Modificadores de Acesso (Access Modifiers), Persistência de Objetos, Design Patterns, SOLID e Refatoração. As linguagens de programação orientadas a objetos, em geral são linguagens fortemente tipadas, como Java, C++, C#, PHP, Python, JavaScript entre outras, oferecem suporte a esses conceitos e permitem aos programadores criar sistemas complexos e modulares, abstraindo a complexidade por meio da representação de objetos e suas interações no mundo real. O paradigma Orientado a Objetos é amplamente utilizado na indústria de software devido à sua capacidade de organizar e modularizar código de maneira eficiente e flexível.
Funcional: Geralmente, é o terceiro paradigma de linguagens de programação de alto-nível que é estudado, onde trabalha com a divisão de problemas através de funções, que resolvem separadamente problemas menores e que, ao serem organizados, resolvem o problema como um todo. A programação funcional pode nos ajudar a reduzir efeitos colaterais e tornar nosso código mais simples de manter. Resumidamente, paradigma de programação é uma forma de classificar linguagens baseando-se em suas funcionalidades e estilo de código. Normalmente, isso vai te guiar na forma que você vai estruturar seu código e desenvolver soluções. Na programação funcional, as funções f(x) são utilizadas para resolver problemas, buscando evitar mutabilidade de dados e estados. Os principais tipos de funções são: Funções de primeira classe, Closures, Imutabilidade de dados, High Order Functions (Funções de Alta Ordem), Funções puras, Funções de ordem superior, Expressões e funções lambdas (Funções Anônimas), Funções Callbacks, Funções Recursivas, Funções Integradas, Built-in Funções de Ordem Superior, Compreensões de Lista, Mapeamento e Redução e Filtragem, Estado Compartilhado, Efeito Colateral, Lazy Evaluation (Avaliação Preguiçosa), Monads, Composição de função e Currying. A Programação Funcional (FP) trata a computação como a avaliação de funções matemáticas e enfatiza o uso de dados imutáveis e expressões declarativas. Linguagens como Haskell, Lisp, Erlang e alguns recursos em linguagens como JavaScript, Python e Scala suportam paradigmas de programação funcional.
Assíncrona: A programação assíncrona refere-se a um estilo de programação que lida com operações que não ocorrem imediatamente e não bloqueiam o fluxo principal de execução do programa. Isso inclui lidar com tarefas como entrada/saída de dados, requisições de rede e operações de longa duração, permitindo que o programa continue executando outras tarefas enquanto aguarda o resultado dessas operações. O paradigma de programação assíncrona refere-se a um estilo de programação que lida com operações que não acontecem imediatamente ou que podem ocorrer em tempos variáveis. Em vez de esperar que uma operação seja concluída para prosseguir, o código assíncrono permite que o programa continue executando outras tarefas enquanto aguarda o resultado da operação assíncrona. Em muitos casos, a assincronicidade é usada para lidar com operações de entrada/saída (I/O), como leitura/gravação de arquivos, chamadas de rede (como requisições HTTP) ou acesso a bancos de dados. Essas operações podem ser demoradas e bloqueantes se executadas de forma síncrona, o que pode resultar em um programa que parece estar "travado" enquanto aguarda a conclusão. Na programação assíncrona, em vez de esperar passivamente pelo término da operação, o código pode ser estruturado para continuar executando outras tarefas ou responder a eventos enquanto a operação assíncrona está em andamento. Quando a operação é concluída, um mecanismo de notificação, como um callback, uma Promise ou async/await em linguagens modernas, é usado para manipular o resultado ou o erro dessa operação. Esse paradigma é essencial em ambientes onde a eficiência e a responsividade são importantes, como em aplicativos da web, servidores e sistemas que precisam lidar com várias operações simultâneas ou operações que podem levar tempo para serem concluídas. A programação assíncrona permite que o código seja mais responsivo, eficiente e capaz de lidar com tarefas concorrentes sem bloquear o fluxo principal de execução.
Reativo: O paradigma de programação reativa é um estilo de desenvolvimento de software que se concentra na criação de aplicações capazes de lidar com a concentração na reatividade a eventos e streams de dados assíncronos. Ele se baseia no princípio de que as mudanças e eventos são constantes, e os sistemas devem reagir a essas mudanças de forma eficiente e automatizada. Ela lida com fluxos de dados e é voltada para lidar com mudanças constantes e eventos em tempo real. Sua ênfase está na resposta a mudanças, na gestão de fluxos de dados e no comportamento reativo do sistema. O paradigma de programação reativa é um estilo de desenvolvimento de software voltado para construir sistemas que reagem e se adaptam dinamicamente a mudanças, eventos e fluxos de dados. Ele se concentra em lidar com a propagação de alterações e na criação de código que responde automaticamente a eventos. Em essência, a programação reativa trata os dados como fluxos contínuos e oferece mecanismos para lidar com eles de forma eficiente. Ela geralmente inclui dois componentes principais: Observables que representam fluxos de dados que podem ser observados. Os Observables emitem notificações sempre que há uma mudança nos dados, permitindo que os observadores reajam a essas mudanças. E Observers que são os componentes que observam (ou "assinam") os Observables e reagem a quaisquer notificações ou mudanças nos dados. Ao utilizar esses conceitos, a programação reativa oferece uma abordagem declarativa para lidar com a reatividade. Em vez de escrever código para manipular explicitamente cada mudança nos dados, os desenvolvedores definem como os dados devem ser tratados quando eles mudam. Isso facilita o desenvolvimento de aplicações que respondem dinamicamente a eventos e atualizações, proporcionando uma maneira mais eficiente e expressiva de lidar com a complexidade dos fluxos de dados em sistemas em tempo real, interfaces de usuário interativas, streaming de dados, entre outros. As linguagens e bibliotecas populares, como RxJS em JavaScript ou ReactiveX em geral, oferecem conjuntos de ferramentas para implementar a programação reativa em várias plataformas e linguagens de programação. A Programação Reativa lida com fluxos de dados assíncronos e a propagação de mudanças. Aplicações orientadas a eventos e aplicações de processamento de dados em streaming se beneficiam da programação reativa.
Genérica: A Programação Genérica visa criar código reutilizável, flexível e independente de tipos, permitindo que algoritmos e estruturas de dados sejam escritos sem especificar os tipos em que operarão. A programação genérica é amplamente utilizada em bibliotecas e frameworks para criar estruturas de dados como listas, pilhas, filas e algoritmos como ordenação e busca.
Programação Orientada a Aspectos (AOP): A programação orientada a aspectos (AOP) visa modularizar preocupações que atravessam múltiplas partes de um sistema de software. O AspectJ é um dos frameworks AOP mais conhecidos que estende o Java com capacidades AOP.
Linear: O paradigma de programação linear refere-se a uma abordagem específica na resolução de problemas de otimização, mais comumente encontrada na matemática e na ciência da computação. Ele se concentra na maximização ou minimização de uma função linear, sujeita a um conjunto de restrições lineares. Essa abordagem é utilizada para resolver problemas complexos de otimização nos quais todos os relacionamentos entre as variáveis são lineares. A função a ser otimizada (a função objetivo) e as restrições devem ser expressas como equações lineares. O método de programação linear utiliza técnicas específicas, como o método simplex, para encontrar a solução ótima para esses problemas. É comumente usado em diversas áreas, como logística, economia, engenharia e planejamento, para resolver problemas de alocação de recursos, programação de produção, design de redes, entre outros. É importante notar que a programação linear é um paradigma específico para um tipo particular de problema de otimização, com suas próprias técnicas e métodos de resolução, e não se refere a um paradigma de programação geral como o funcional, orientado a objetos ou reativo.
Multi-paradigma: A combinação de paradigmas imperativo e orientado a objetos é uma prática comum e pode ser extremamente útil na programação. Ela permite que você escolha a abordagem mais adequada para cada parte de seu código, tirando proveito dos benefícios de ambos os paradigmas, conforme necessário para resolver problemas específicos. Você também pode usar o paradigma funcional em conjunto com o paradigma de programação orientada a objetos (POO) e o paradigma imperativo, essa combinação de paradigmas é conhecida como programação multi-paradigma e é suportada por muitas linguagens de programação modernas. A escolha de usar programação funcional em conjunto com POO e imperativo depende dos requisitos do projeto e das preferências da equipe de desenvolvimento. Em muitos casos, a combinação de paradigmas pode resultar em código mais expressivo, reutilizável e robusto, permitindo que você aproveite o melhor de cada paradigma para atender às necessidades do seu sistema.
Dinâmica: O paradigma de programação dinâmica é uma abordagem algorítmica para resolver problemas computacionais complexos, geralmente problemas de otimização, dividindo-os em subproblemas menores e resolvendo cada subproblema apenas uma vez. Em seguida, armazena-se os resultados para reutilização futura, evitando recálculos desnecessários. Essa técnica é comumente utilizada para problemas em que a solução ótima pode ser alcançada através da combinação de soluções ótimas de subproblemas menores. A ideia central é que, se você já resolveu um subproblema em particular, não precisa resolvê-lo novamente; basta usar o resultado armazenado. A programação dinâmica é diferente da divisão e conquista, pois a divisão e conquista resolve cada subproblema separadamente e não armazena seus resultados para reutilização. A abordagem de programação dinâmica geralmente envolve dois métodos principais: Top-Down (Memoization) que começa resolvendo o problema original, dividindo-o em subproblemas menores e armazenando os resultados desses subproblemas para reutilização. Evita recálculos repetidos. O Bottom-Up (Tabulation) que começa resolvendo os subproblemas menores e, gradualmente, avança para o problema original, combinando os resultados dos subproblemas menores para encontrar a solução do problema original. Usa tabelas (ou matrizes) para armazenar os resultados dos subproblemas. Então, a programação dinâmica é comumente usada em problemas de otimização, como encontrar o caminho mais curto em um grafo, a subsequência comum mais longa em duas sequências, a mochila com a melhor combinação de itens, entre outros. É uma técnica poderosa para resolver problemas complexos de forma eficiente, reduzindo a complexidade temporal e espacial através da reutilização de resultados de subproblemas. A programação dinâmica é de fato um paradigma que faz um uso particularmente significativo e eficiente de estruturas de dados e algoritmos. Essa técnica é notável por sua abordagem sistemática para resolver problemas de otimização, dividindo-os em subproblemas menores e armazenando os resultados para evitar recálculos desnecessários.
Concorrência: O paradigma de concorrência refere-se à capacidade de um sistema lidar com múltiplas tarefas simultaneamente, permitindo que diferentes partes de um programa sejam executadas de forma independente e em paralelo. A concorrência é especialmente relevante em sistemas computacionais modernos, onde há múltiplos processadores, núcleos de CPU ou mesmo múltiplos sistemas operacionais em execução ao mesmo tempo. Existem dois principais modelos de concorrência: Concorrência baseada em processos onde nesse modelo, processos separados são executados independentemente uns dos outros. Cada processo pode conter múltiplas threads, que são unidades menores de execução. Os processos compartilham recursos por meio de mecanismos como memória compartilhada ou troca de mensagens. Sistemas operacionais modernos utilizam esse modelo para gerenciar vários processos concorrentes. Concorrência baseada em threads: Aqui, threads separadas dentro de um mesmo processo são executadas de forma independente. As threads compartilham o mesmo espaço de memória e recursos do processo pai. Esse modelo é mais leve em termos de recursos do sistema, mas requer sincronização cuidadosa para evitar problemas como condições de corrida (quando múltiplas threads tentam acessar ou modificar um recurso compartilhado ao mesmo tempo). A concorrência é crucial para melhorar o desempenho de sistemas, especialmente em operações intensivas, como processamento de dados em paralelo, execução de tarefas em segundo plano, comunicação entre sistemas distribuídos e muito mais. No entanto, a programação concorrente pode ser complexa devido a desafios como condições de corrida, deadlock (bloqueio), sincronização e comunicação entre processos ou threads. Linguagens de programação oferecem diferentes mecanismos para lidar com a concorrência, como mutexes, semáforos, variáveis de condição, entre outros, facilitando o desenvolvimento de sistemas que podem tirar proveito da execução simultânea de tarefas. A Programação Concorrente lida com a execução de múltiplas tarefas ou processos simultaneamente, melhorando o desempenho e a utilização de recursos. A programação concorrente é utilizada em várias aplicações, incluindo servidores multithread, processamento paralelo, servidores web concorrentes e computação de alto desempenho.
Como mencionado anteriormente, a escolha da linguagem de programação logo no início do desenvolvimento é essencial, pois uma mudança mais adiante pode comprometer os prazos de entrega. Para fazer essa escolha, além das considerações relacionadas a licenças e capacidade de produção da equipe de desenvolvedores, existem algumas propriedades que são desejáveis em uma linguagem de programação (VAREJÃO, 2004):
-
Legibilidade: Diz respeito à facilidade de entendimento de um programa. Um exemplo da falta de legibilidade está no uso do operador
*na linguagem C, como nessa linha de código:*a = a*(*b), em que o operador está sendo usado tanto para a operação de multiplicação como uma referência para memória (ponteiro). -
Redigibilidade: Relaciona-se com a facilidade de escrever o código permitindo que o programador se concentre na descrição do algoritmo que resolve o problema, ao invés de detalhes da sintaxe. Um exemplo está no uso da linguagem python para fazer a atribuição de valor para uma variável.
-
Confiabilidade: Garante que um programa não se comporte de modo inesperado. Por exemplo, em java é feita a verificação da dimensão de um vetor, quando é feita uma atribuição de um valor para uma determinada posição.
-
Eficiência: Trata da melhor utilização dos recursos computacionais disponíveis. Um exemplo é a velocidade do compilador, ou interpretador da linguagem de programação.
-
Facilidade de aprendizado: Relacionada às características sintáticas da linguagem, ou seja, de quantos modos distintos, ou quão complexo, pode ser escrever operações semelhantes e, claro, quanto treinamento está disponível sobre a linguagem de programação.
-
Ortogonalidade: O controle de funções independentes deve ser feito por mecanismos independentes; isto quer dizer que, quando uma instrução é executada, nada além dessa instrução acontece. Um exemplo de sistema ortogonal ocorre no uso de aparelho de rádio, no qual a mudança de estação não altera o volume e vice-versa.
Quanto mais ortogonal for a linguagem de programação, menos exceções às regras. A ortogonalidade evita que situações semelhantes sejam tratadas de formas distintas. Isso ajuda o desenvolvedor a se concentrar na solução do sistema e reduz o tempo necessário para aprender as regras sintáticas da linguagem de programação.
Além dos itens desejáveis em uma linguagem de programação, também devem ser consideradas as seguintes questões de ordem prática:
- Como funciona o suporte?
- O suporte está disponível para o idioma local?
- Existe expectativa de uso no longo prazo?
- Em que ambiente o projeto será desenvolvido: Web, dispositivos móveis etc.?
- Quais as considerações de infraestrutura que devem ser levadas em consideração?
- Como será a implantação?
- Já existe um padrão com bibliotecas, recursos e ferramentas específicas para esse tipo de projeto?
- Os desenvolvedores já têm experiência com essa linguagem?
- Quais treinamentos são necessários para aprender a programar?
- Quais itens são negociáveis no projeto: Tempo, orçamento, recursos?
- O que se espera em relação ao desempenho do projeto?
- É necessário que haja integração com ferramentas de terceiros?
- Existem considerações de segurança?
São muitas questões que devem ser consideradas na escolha da linguagem da programação, mas que, se respondidas no momento do planejamento, podem evitar muitos problemas mais adiante.
As linguagens de programação devem ser escolhidas com o contexto para o qual elas devem ser aplicadas. Abaixo, segue uma lista das principais linguagens de programação classificadas com a contextualização da sua aplicação (ver Top 43 Programming Languages: When and Howto Use Them, 2020):
|
Aplicações Web |
javascript, PHP, Ruby, HTML / CSS, TypeScript |
|
Aplicações móveis |
Swift, Java, Kotlin, Objective-C |
|
Sistemas operacionais |
C, C++, Assembly |
|
Aplicações de propósito geral (corporativas) |
Java, C#, C++ |
|
Análise e aprendizado de máquina |
Python, R, Clojure, Julia |
|
Matemática e computação científica |
Matlab, Fortran, Julia, R, C++ |
|
Visualização de dados Python |
Python, R, Java, C# |
|
Big Data |
Java, Python, R, Scala, Clojure |
|
Armazenamento de dados |
SQL, C#, Java, Python |
Existem muitas outras linguagens de programação além das mencionadas nessa lista. Uma das razões que explicam a existência de tantas linguagens é a necessidade de resolver problemas mais específicos, como, por exemplo, o desenvolvimento de aplicações para dispositivos móveis.
As linguagens Java e C++ são de propósito geral e, apesar de poderem ser usadas para análise e aprendizado de máquina, não são adequadas para esta finalidade. As linguagens mais usadas para esse propósito são Python e R.
A escolha da linguagem de programação tem impacto em todas as etapas do projeto e, se feita na época certa e considerando as diversas questões tratadas nesse texto, pode dar estabilidade para o desenvolvimento do sistema. A linguagem de programação ideal conduz o projeto para atingir seu propósito no prazo combinado.
x<- 10;
Se(x > 100)Então
Escreva("Maior que 100")
Senão
Escreva("Menor que 100");
Se(x divisível 10)Então
Escreva("x é divisível por 10")
Senão
Escreva("x não é divisível por 10")O primeiro comando “x <- 10” é realizado de qualquer modo. Em seguida, o programa tem dois caminhos possíveis a partir do comando “Se(x > 100)Então”. Mais adiante, o programa tem mais dois possíveis caminhos a partir do comando “Se(x divisível 10)Então”. Portanto, o total de caminhos possíveis é a contagem de todos os caminhos no fluxo de execução.
A decisão de escolher a linguagem de programação tem forte impacto em todas as etapas do projeto e no planejamento das equipes envolvidas. Portanto, é fundamental que ocorra logo no início do projeto, na fase de planejamento, para que as equipes possam se organizar sobre o processo de desenvolvimento. Para o desenvolvimento de um sistema deve levar em consideração alguns pré-requisitos:
- Licenças comerciais ou de código aberto
- Conhecimento técnico da equipe
- Suporte do fornecedor
- Requisitos para fazer a implantação no cliente
- Capacidade de dar manutenção posteriormente.
Exemplo de stacks: .NET, Node.js, Ruby, Java, PHP, Python, Go, Scala, Clojure, Elixir e Rust.
-
Por ter um grande impacto no desenvolvimento do projeto, esses pré-requisitos devem ser levados em consideração na fase inicial de planejamento, para que os desenvolvedores recebam os treinamentos necessários.
-
Servem também para que outras equipes (de suporte ao desenvolvimento do projeto, como arquitetos de software e responsáveis pela confecção de artefatos que dependem da tecnologia selecionada) possam se organizar com antecedência, fazendo com que o fluxo de trabalho aconteça normalmente.
-
Essa decisão deve ser tomada logo no início, pois em etapas posteriores pode inviabilizar a continuidade do desenvolvimento, quando, por exemplo,for necessário escalar os sistemas, ou atualizá-los.
A escolha da linguagem de programação deve levar em consideração requisitos técnicos, comerciais e disposição de recursos que viabilizem a sua aplicação. A “modernidade da linguagem” por si só não satisfaz a nenhum desses critérios.
Linguagens fortemente tipadas Linguagens fracamente tipadas Semelhanças entre linguagens Baseadas de outras linguagens
A taxonomia de linguagens de programação é uma classificação ou sistema de categorização que visa agrupar e organizar as linguagens de programação com base em características, propósitos, paradigmas de programação, características sintáticas e semânticas, e outros critérios relevantes. Essa classificação ajuda os programadores, pesquisadores e educadores a entender melhor as linguagens de programação, suas características e aplicações, bem como a escolher a linguagem adequada para tarefas específicas.
A taxonomia de linguagens de programação pode incluir várias categorias e subcategorias. Aqui estão alguns dos critérios comuns usados para classificar linguagens de programação:
-
Paradigma de Programação: Linguagens podem ser categorizadas com base no paradigma de programação predominante que elas suportam. Alguns paradigmas comuns incluem programação orientada a objetos, programação funcional, programação procedural, programação lógica, entre outros.
-
Tipo de Dados: Algumas linguagens são classificadas com base no sistema de tipos que elas usam, como linguagens de tipagem estática, dinâmica, forte ou fraca.
-
Domínio de Aplicação: As linguagens podem ser agrupadas com base em seu domínio de aplicação principal, como linguagens de script para web, linguagens de sistemas de baixo nível, linguagens de análise de dados, linguagens para desenvolvimento mobile, etc.
-
Popularidade: Algumas taxonomias também levam em consideração a popularidade e o uso atual das linguagens, dividindo-as em linguagens amplamente adotadas e linguagens de nicho.
-
Sintaxe e Semântica: As diferenças na sintaxe e semântica das linguagens também podem ser usadas para categorizá-las. Por exemplo, algumas linguagens são conhecidas por sua sintaxe concisa, enquanto outras têm uma sintaxe mais verbose.
-
História e Origem: A origem e a história das linguagens também podem ser usadas como critérios de classificação. Algumas linguagens foram criadas para fins específicos ou evoluíram a partir de outras linguagens.
-
Implementação: A forma como as linguagens são implementadas, como compiladas ou interpretadas, também pode ser considerada ao classificar linguagens de programação.
-
Comunidade e Ecossistema: A presença de uma comunidade ativa de desenvolvedores e um ecossistema de bibliotecas e ferramentas pode ser relevante para a classificação de linguagens.
É importante observar que não há uma única taxonomia universalmente aceita para linguagens de programação, e diferentes fontes podem usar abordagens ligeiramente diferentes. No entanto, a taxonomia ajuda a compreender a diversidade de linguagens disponíveis e a escolher a linguagem mais apropriada para uma tarefa específica com base em suas características e requisitos.
Um ponto muito importante sobre taxonomia de uma linguagem de programação é sobre o uso de framework para as linguagens de programação que nada mais é do que uma estrutura que serve de base para a construção de aplicações e eles atendem a diferentes necessidades e níveis de experiência de usuário. Ele é uma arquitetura de programação que reúne uma variedade de códigos genéricos com o objetivo de simplificar, estruturar e facilitar o processo de desenvolvimento. Os frameworks são desenvolvidos a partir de diferentes linguagens de programação e, na hora de escolher um framework, é necessário estar de acordo com a sua linguagem nativa. Eles podem ser front-end ou back-end. Os frameworks são como um esqueleto pré-definido que permite construir sites, aplicativos e softwares, alterando apenas as particularidades que são muito trabalhosas e até árduas se forem feitas manualmente por processos pelo desenvolvedor, ou seja, isso permite que os desenvolvedores economizem tempo e se concentrem em partes mais complexas e específicas do software que estão desenvolvendo. Por exemplo, existem frameworks específicos para o desenvolvimento de aplicativos, para a manipulação de bancos de dados, para a programação de games, para o desenvolvimento de redes sociais, etc. Portanto, um framework de linguagem de programação é uma ferramenta poderosa que pode aumentar a eficiência e a produtividade dos desenvolvedores em propor soluções ou resolver problemas complexos.
O processo híbrido de implementação de uma linguagem de programação combina a execução rápida dos tradutores (compiladores) com a portabilidade dos interpretadores. O segredo é a geração de um código intermediário mais facilmente interpretável, porém não preso a uma plataforma (SO/Hardware).
Esse código intermediário não é específico para uma plataforma, possibilitando aos programas já compilados para esse código serem portados em diferentes plataformas, sem alterar e nem fazer nada. Para cada plataforma desejada devemos ter um interpretador desse código.
Duas importantes linguagens implementaram essa solução, com diferentes formas usando máquinas virtuais: Python e Java.
O compilador é o elemento central do processo de tradução, responsável pelo custo de compilação, visto no modulo anterior. Em função dessa relevância, muitas vezes o processo como um todo é erroneamente chamado de compilação, uma vez que o ambiente integrado das linguagens atuais já integra todos os componentes (montador, compilador, carregador e ligador) quando necessário.
O projeto da linguagem tem no compilador a sua figura central.
A imagem abaixo ilustra os componentes envolvidos na compilação de um programa fonte:
Abaixo, vamos entender cada fase da compilação:
Nesse processo de conversão, o programa escrito em uma linguagem de alto nível é traduzido para uma versão equivalente em linguagens de máquina, antes de ser executado. O processo de tradução pode ser executado em várias fases, que podem ser combinadas e executadas em simultaneidade. O processo de tradução é erroneamente chamado de compilação, que na verdade é uma de suas fases.
As fases que compõem o tradutor, ou seja, iniciando na leitura do programa-fonte (linguagem de alto nível) e terminando com a geração do código executável (entendido pela máquina), são: Compilação, Montagem, Carga e Ligação. A imagem abaixo ilustra o processo de tradução.
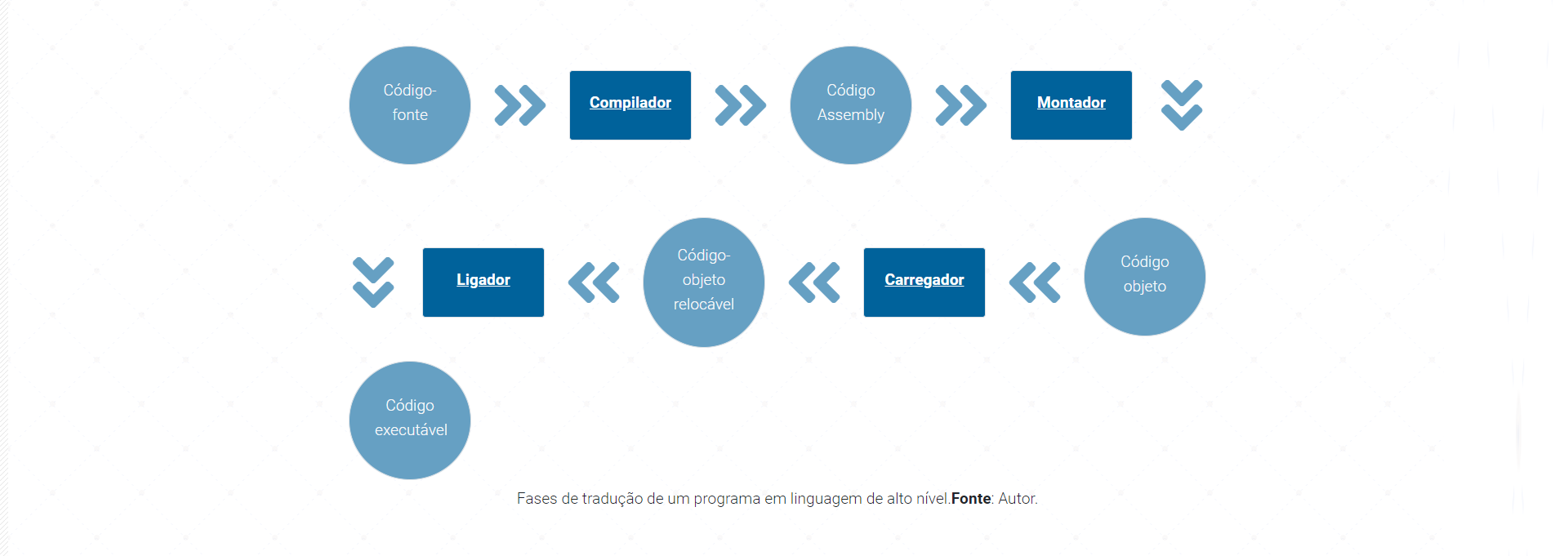
O compilador (detalhes adiante) analisa o código-fonte e estando tudo OK, o converte para um código Assembly (da máquina hospedeira).
O montador traduz o código Assembly para o código de máquina intermediário (Código-objeto), que não é executável pelo computador. O código-objeto pode ser relocável, ou seja, carregado em qualquer posição de memória ou absoluto, carregado em um endereço de memória específico. A opção relocável é mais comum e mais vantajosa.
O Ligador liga (ou linka) o código-objeto relocável com as rotinas bibliotecas (outros objetos, rotinas do SO, DLLs etc.), usadas nos códigos-fontes. Essa ligação gera o código executável.
O carregador é que torna o código-objeto em relocável.
Identifica os tokens (elementos da linguagem), desconsidera partes do código-fonte, como espaços em branco e comentários e gera a Tabela de símbolos, com todos esses tokens, que são identificadores de variáveis, de procedimentos, de funções, comandos, expressões etc.
Verifica se os tokens são estruturas sintáticas (exemplos: expressões e comandos) válidas, aplicando as regras gramaticais definidas no projeto da linguagem.
Verifica se as estruturas sintáticas possuem sentido. Por exemplo, verifica se um identificador de variável ou constante é usado adequadamente, se operandos e operadores são compatíveis. Monta a árvore de derivação conforme ilustrado abaixo para formação das expressões.
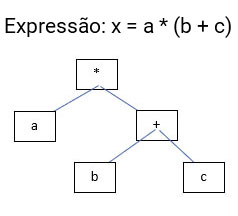
GERADOR DE CÓDIGO INTERMEDIÁRIO, OTIMIZADOR DE CÓDIGO E GERADOR DE CÓDIGO
Em distintas fases geram o programa-alvo ou programa-objeto.
- Gerador de código intermediário, que contém toda a informação para gerar o código-objeto.
Na imagem a seguir, o código intermediário está representado no último quadro – código em Assembly:
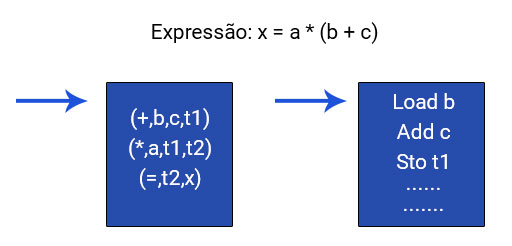
- O otimizador tem por objetivo eliminar redundâncias do código intermediário e tornar o objeto mais enxuto e eficiente.
TRATADOR DE ERROS: Em todas as fases existem erros: léxicos, sintáticos e semânticos. Um bom compilador apresenta uma boa tratativa de erros.
Mantém a tabela de símbolos atualizada a cada passo do compilador.
Warning
As principais características dos compiladores são:
- Gerar código-objeto mais otimizado.
- Execução mais rápida que o processo de interpretação.
- Traduz um mesmo comando apenas uma vez, mesmo que usado em várias partes do programa – tanto iterações como repetição de código.
- Processo de correção de erros e depuração é mais demorado.
- A programação final (código-objeto) é maior.
- O programa-objeto gerado é dependente de plataforma — processador + SO (Sistema Operacional) — necessitando de um compilador diferente para cada família de processadores/sistema operacional.
Um recompilador é um tipo de software que converte o código de máquina ou bytecode de um programa para outro formato de código de máquina ou bytecode. Isso permite que o programa seja executado em uma plataforma diferente daquela para a qual foi originalmente compilado.
Um recompilador é um tipo especial de programa ou componente de software responsável por traduzir, durante a execução ou antes dela, um código de máquina ou código intermediário de uma plataforma para outro formato mais apropriado para ser executado em uma arquitetura diferente ou otimizada. Essa tradução pode ocorrer em tempo real (dinamicamente) ou de forma estática (antes da execução), dependendo da abordagem adotada pelo sistema. Seu papel é essencial em sistemas que precisam executar instruções originalmente escritas para outra plataforma, permitindo compatibilidade entre diferentes hardwares ou arquiteturas de software.
Em contextos como emuladores e máquinas virtuais, o recompilador é particularmente útil para melhorar o desempenho. Por exemplo, em um emulador de videogame, o recompilador dinâmico pode converter blocos de código do console original (como um PlayStation ou Nintendo 64) para um código equivalente otimizado para a CPU moderna do computador onde está sendo rodado. Em vez de interpretar cada instrução uma por uma, o recompilador agrupa várias instruções, traduz tudo de uma vez e armazena esse novo código já adaptado, pronto para ser executado rapidamente. Isso é chamado de "dynamic recompilation" ou "just-in-time recompilation".
Além disso, recompiladores também são encontrados em ambientes como a JVM (Java Virtual Machine) ou o CLR (.NET), que convertem bytecodes intermediários em código nativo durante a execução, melhorando o desempenho das aplicações. O termo "recompilador" também pode aparecer em engenharia reversa, onde se tenta reconstruir um código-fonte ou gerar código equivalente a partir de executáveis, mas nesse caso o foco é mais na análise e transformação de código binário.
Portanto, o recompilador é uma ferramenta que permite a portabilidade, compatibilidade e otimização entre diferentes camadas de software e hardware, sendo essencial em diversas aplicações modernas, como emuladores, máquinas virtuais, depuradores e mecanismos de execução de linguagens de alto nível.
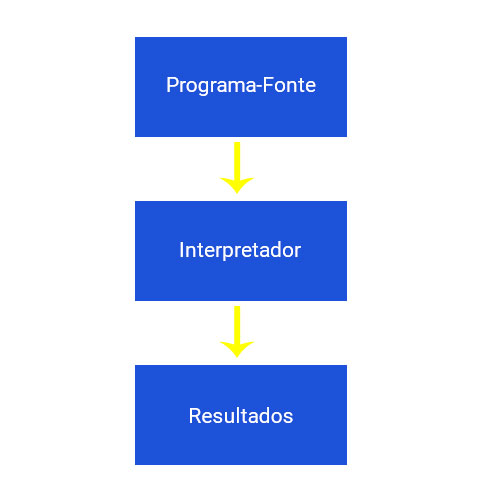
A imagem ao lado ilustra o simples processo de Interpretação:
Na conversão por interpretação, cada comando do programa-fonte é traduzido e executado (um a um) imediatamente. O interpretador traduz um comando de cada vez e chama uma rotina para completar a sua execução.
O interpretador é um programa que executa repetidamente a seguinte sequência:
1 - Obter a próxima instrução do código-fonte. >> 2 - Interpretar a instrução (conversão para comandos em linguagem de máquina). >> 3 - Executar a instrução.
Perceba que o procedimento, acima descrito, é bastante similar àquele executado por computadores que implementam a máquina de Von Neumann, na execução de uma instrução, conforme a seguir:
- Obter a próxima instrução.
- CI → endereço da próxima instrução. CI = contador de instruções.
- RI → instrução a ser executada. RI = registrador de instruções.
- Decodificar a instrução.
- Executar a instrução.
Dentre as principais características do interpretador, podemos citar:
- Atua a cada vez que o programa precisa ser executado.
- Não produz programa-objeto persistente.
- Não traduz instruções que nunca são executadas.
- O resultado da conversão é instantâneo: resultado da execução do comando ou exibição de erro – interpretador puro.
- Útil ao processo de depuração de código devido a mensagens de erros em tempo de execução (tanto análise sintática como semântica).
- Execução mais lenta do que outros processos de tradução (compilação), pois toda vez que o mesmo programa é executado, os mesmos passos de interpretação são executados.
- Consome menos memória.
- O Código-fonte é portátil.
- Não é gerado um código de máquina.
- Pode executar o comando em alto nível diretamente ou gerar um código intermediário, que neste caso é interpretado por uma máquina virtual (VM). – Interpretador híbrido.
- Se a máquina virtual foi desenvolvida para diferentes plataformas, temos a portabilidade do código-fonte. Este é o caso da linguagem Java.
Tradução x interpretação:
| Vantagens | Desvantagens | |
|---|---|---|
| Tradutores | 1. Execução mais rápida 2. Permite estruturas de programas mais complexas. 3. Permite a otimização de código. | 1. Várias etapas de conversão. 2. Programação final é maior, necessitando de mais memória para sua execução. 3. Processo de correção de erros e depuração é mais demorado. |
| Interpretadores | 1. Depuração mais simples. 2. Consome menos memória. 3. Resultado imediato do programa (ou parte dele). | 1. Execução do programa é mais lenta. 2. Estruturas de dados demasiado simples. 3. Necessário fornecer o código fonte ao utilizador. |
O processo híbrido de implementação de uma linguagem de programação combina a execução rápida dos tradutores (compiladores) com a portabilidade dos interpretadores. O segredo é a geração de um código intermediário mais facilmente interpretável, porém não preso a uma plataforma (SO/Hardware).
Esse código intermediário não é específico para uma plataforma, possibilitando aos programas já compilados para esse código serem portados em diferentes plataformas, sem alterar e nem fazer nada. Para cada plataforma desejada devemos ter um interpretador desse código.
Duas importantes linguagens implementaram essa solução, com diferentes formas usando máquinas virtuais: Python e Java.
Ou, simplesmente, aplicativo ou app (mundo mobile), que visa oferecer ao usuário facilidades para realizar uma tarefa laboral ou de lazer.

Compreende programas essenciais ao funcionamento do computador. O sistema operacional é o principal exemplo.
Uma linguagem de programação é um software básico, que permite ao programador escrever outros programas de computador, seja ela um software aplicativo ou básico.
A codificação de um programa em uma linguagem de programação, chama-se programa-fonte, que ainda não pode ser entendido e executado pelo hardware do computador, pois este apenas entende a linguagem de máquina ou linguagem binária, na qual cada instrução é uma sequência de bits (0 ou 1).
Uma linguagem de programação é um formalismo com um conjunto de símbolos, palavras reservadas, comandos, regras sintáticas e semânticas e outros recursos, que permitem especificar instruções de um programa.
As linguagens de programação surgiram da necessidade de livrar o programador dos detalhes mais íntimos das máquinas em que a programação é feita, permitindo a programação em termos mais próximos ao problema, ou em nível mais alto.
A produtividade de um programador ao escrever código em uma linguagem de programação está intimamente relacionada à facilidade de aprendizado, leitura e escrita de programas naquela linguagem, somada a expertise do programador no contato com a linguagem.
Isto é, quanto mais o programador conhecer as propriedades superlativas daquela linguagem, melhores e mais eficientes serão os códigos escritos.
Precisamos de uma linguagem em que os humanos possam escrever os seus programas e uma linguagem que os computadores possam utilizar para executar os programas, uma linguagem que seja muito mais complexa do que a linguagem das máquinas e, no entanto, muito mais simples do que a linguagem natural.
Tais linguagens são muitas vezes chamadas linguagens de programação de alto nível. São pelo menos um pouco semelhantes aos naturais na medida em que utilizam símbolos, palavras e convenções legíveis para os seres humanos. Estas linguagens permitem aos seres humanos expressar comandos a computadores que são muito mais complexos do que os oferecidos pelas ILs.
Um programa escrito numa linguagem de programação de alto nível é chamado source code, também conhecido como código-fonte (em contraste com o ee executado por computadores). Da mesma forma, o ficheiro que contém o source code chama-se source file, també conhecido como arquivo-fonte.
A programação informática é o ato de compor os elementos da linguagem de programação selecionada pela ordem que provocará o efeito desejado. O efeito pode ser diferente em cada caso específico - depende da imaginação, conhecimento e experiência do programador.
É claro que tal composição tem de ser correta em muitos sentidos:
- alfabeticamente - um programa precisa de ser escrito num guião reconhecível, tal como romano, cirílico, etc.
- lexicamente - cada linguagem de programação tem o seu dicionário e é preciso dominá-lo; felizmente, é muito mais simples e menor do que o dicionário de qualquer língua natural;
- sintaticamente - cada linguagem tem as suas regras, e estas devem ser obedecidas;
- semanticamente - o programa tem de fazer sentido.
Infelizmente, um programador também pode cometer erros com cada um dos quatro sentidos acima referidos. Cada um deles pode fazer com que o programa se torne completamente inútil.
Vamos supor que tenha escrito um programa com sucesso. Como persuadir o computador a executá-lo? Tem de transformar o seu programa em linguagem de máquina. Felizmente, a tradução pode ser feita pelo próprio computador, tornando todo o processo rápido e eficiente.

Considere a arquitetura simplificada de um computador apresentada na figura 1. Nela, apresentamos o processador com três registradores (R0, R1 e R2), os barramentos de dados e endereços e a memória que possui 8 células, numeradas de 0 a 7.
Atenção: Vários componentes como registrador de instruções, contador de instruções unidade aritmética e lógica e outros componentes foram intencionalmente omitidos para focarmos apenas nos que são interessantes em nossa explicação.
Imagine agora que você deseja executar a seguinte operação:
A := B + COnde A, B e C são variáveis mapeadas respectivamente para as posições 5, 6 e 7 da memória.
Considere ainda que B e C possuem os valores 10 e 8 e já estão armazenados na memória, conforme será apresentado na Figura 2.
Atenção: Para fins meramente didáticos, os valores são apresentados em decimal e não em binário, como efetivamente, ficam na memória.

Um processador executa comando em linguagem de máquina cujos comandos podem ser, de forma simplificada, divididos em código de operação e um ou mais endereços (Figura 3), constituindo, cada um deles, um conjunto de bits.
| Formato de instrução | ||
| Código Operação | Endereço | Endereço |
Para continuarmos nosso exemplo, vamos considerar que o processador possui as seguintes instruções:
| Nr | Instrução | Código de operação |
| 1 | Ler um dado da memória para um registrador. | 00 |
| 2 | Somar um dado de um registrador com o R0 armazenando o resultado em R0. | 01 |
| 3 | Gravar o dado de um registrador em uma posição de memória. | 10 |
A partir deste conjunto de instruções, o programa seria então traduzido como:
LER B para R0
LER C para R1
SOMAR R0 a R1
GRAVAR R0 em A

Imagine que você deseja montar um computador. Você vai a uma loja de venda de equipamentos e compra os componentes, placa-mãe, HD, memória RAM, fonte etc e pede para um técnico montá-los.
Pronto? Claro que não! Você não tem como interagir com ele sem os dispositivos de E/S, no caso o monitor, mouse e teclado.
Agora, você liga o computador e ele executa o boot.
E nada...
Reboot and Select proper Boot device or Insert Boot Media in selected Boot device
A mensagem acima é do POST para inserir a imagem do SO. O que aconteceu? Faltou o sistema operacional, o hardware do computador sem o sistema operacional é apenas um conjunto de componentes eletrônicos incapazes de serem utilizados de forma produtiva pelo usuário.
Em um computador, o sistema operacional pode ser definido como o conjunto de programas que servem de interface entre o hardware e o usuário. Ele é composto por rotinas que realizam o gerenciamento de diversos componentes do sistema (processador, memória, dispositivos de entrada e saída etc).
Desta forma, o SO torna transplante ao usuário toda a complexidade da manipulação do hardware, criando uma camada de abstração (tal qual uma máquina virtual) entre o usuário e os dispositivos eletrônicos.
Sistema operacional como uma camada de abstração:
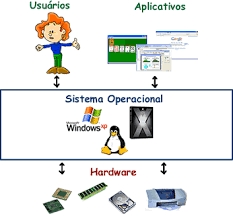
Dada existência de software como o sistema operacional, os programas normalmente são classificados como software básico (inclui o Sistema Operacional), e softwares de aplicação, que são voltados a resolver problemas dos usuários.
Diagrama de interação entre Hardware, Software básicos e aplicativos:
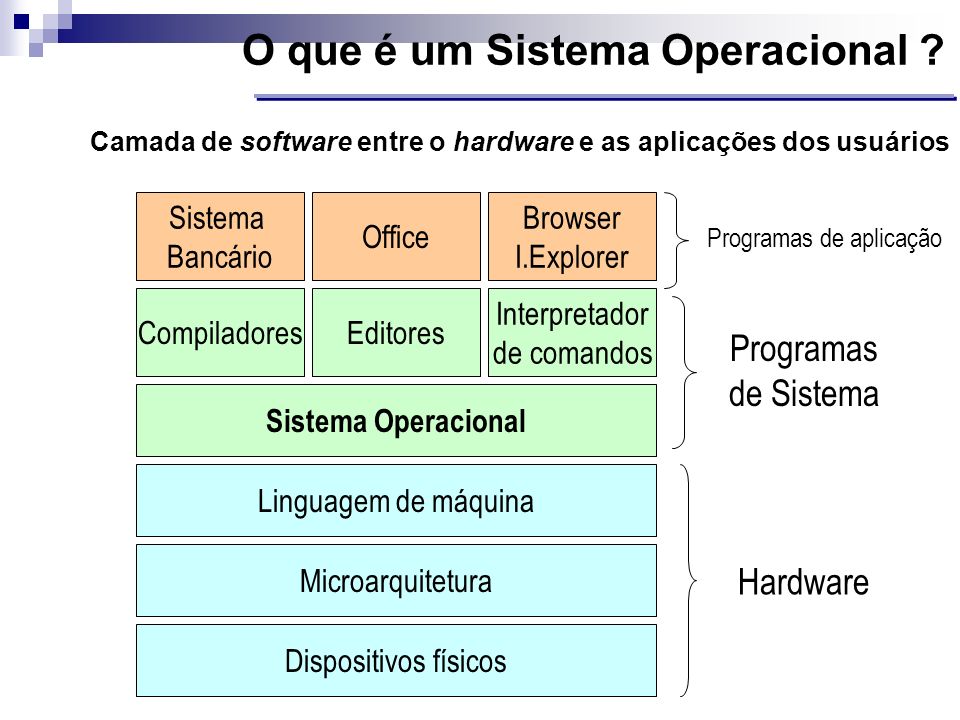
São os dispositivos eletrônicos em si, como o processador, os chips de memória, controladores de disco, teclado e outros dispositivos, barramentos e etc.
De forma geral, são pequenos passos, denominados micro-operações, que formam, uma instrução de processador completa, como ADD, MOV, JMP etc.
O conjunto de instruções do computador é chamado de linguagem de máquina, e apesar de ser uma espécie de linguagem, podemos dizer que faz parte do Hardware porque os fabricantes as incluem nas especificações do processador, para que os programas possam ser escritos.
Obs: As instruções também incluem, geralmente, operações que permitem ao processador comunicar-se com o mundo externo, como controladores de disco, memória, teclado etc.
Como a complexidade para acesso a dispositivos é muito grande, é tarefa do SO "esconder" estes detalhes dos programas. Assim, o SO pode, por exemplo, oferecer aos programas uma função do tipo "Leia um Bloco de um arquivo", e os detalhes de como fazer isso ficam a cargo do SO.
Software Básico ou programação do sistema, acima do SO, estão os demais programas que são utilizados pelo usuário final (como, por exemplo: compiladores, editores e interface de linha de comando - CLI), mas alguns deles ainda são considerados softwares básicos como o SO.
Entre eles podemos citar o Interpretador de comandos, Shell, que consiste a interface com o usuário.
Obs: Nos SOs atuais, frequentemente o Shell é uma interface gráfica (ou inglês, GUI - Graphics User Interface ou CLI - Command Line Interface).
Raramente numa interface bem elaborada, o usuário precisa digitar comandos para o computador (Como era no caso do antigo MS-DOS). A maneira mais comum, é através do uso de mouse e teclado, e atualmente existem sensores de touch para computadores mais sofisticados.
Nos tempos do falecido MS-DOS, o teclado era apenas o dispositivo de entrada dominante, por onde o usuário entrava todos os comandos para realizar suas tarefas.
O que é importante observar é que a respeito do software básico, apesar de que editores (bloco de notas, nano, Vim), compiladores (C ou UNIX) e interpretadores de comandos (command.com ou explorer.exe no Windows) normalmente serem instalados junto com o SO, eles não são o SO.
Portanto, o Shell ou Bash que normalmente usamos em um SO nada mais é do que um programa que utiliza serviços do SO, mas com a finalidade de permitir que os usuários realizem suas tarefas mais frequentes: executar programas e trabalhar com arquivos.
O Shell — sendo o Bash (Bourne Again Shell) um dos mais populares — é uma interface entre o usuário e o sistema operacional. Ele funciona como um interpretador de comandos, permitindo que o usuário interaja com o núcleo do sistema (o kernel) por meio de comandos de texto. Esses comandos podem ser usados para realizar tarefas como navegar entre diretórios, copiar, mover ou deletar arquivos, executar programas, monitorar processos e configurar o ambiente de execução.
Embora pareça algo independente, o Shell é apenas mais um programa rodando sobre o sistema operacional, com a diferença de que serve como ponte principal entre o usuário e o sistema. Ele usa chamadas de sistema (system calls) para solicitar que o kernel execute ações, como leitura de arquivos ou alocação de memória. E justamente por ser um programa acessível via terminal, é possível automatizar tarefas com scripts, tornando-o uma ferramenta poderosa para administração de sistemas, automação de processos e controle de ambientes de desenvolvimento.
A grande diferença entre o SO e os programas que rodam sobre ele, sejam software básico ou software aplicativo, é que o SO roda em modo kernel (ou supervisor) enquanto os demais programas rodam em modo usuário.
Estes dois modos de operação dos processadores diferem no fato de que em modo supervisor, um programa tem acesso a todo o hardware, enquanto os programas que rodam em modo usuário, tem acesso somente a determinadas regiões de memória, não podem acessar dispositivos diretamente e precisam pedir para o SO quando necessitam de alguma tarefa especial.
Isto garante que os programas dos usuários, não acabem por invadir áreas de memória do SO, e acabem por "travar" o sistema. Isto também possibilita que programas de diferentes usuários estejam rodando na mesma máquina, de forma que um usuário não consiga interferir no programa de outro.
A grande diferença entre o SO e os programas que rodam sobre ele, sejam software básico ou software aplicativo, é que o SO roda em modo kernel (ou supervisor) enquanto os demais programas rodam em modo usuário.
Estes dois modos de operação dos processadores diferem no fato de que em modo supervisor, um programa tem acesso a todo o hardware, enquanto os programas que rodam em modo usuáriom tem acesso somente a determinadas regiões de memória, não podem acessar dispositivos diretamente e precisam pedir para o SO quando necessitam de alguma tarefa especial.
Isto garante que os programas dos usuários, não acabem por invadir áreas de memória do SO, e acabem por "travar" o sistema. Isto também possibilita que programas de diferentes usuários estejam rodando na mesma máquina, de forma que um usuário não consiga interferir no programa de outro.
As estruturas de dados é o ramo da computação que estuda os diversos mecanismos de organização de dados para atender aos diferentes requisitos de processamento. As estruturas de dados definem a organização, métodos de acesso e opções de processamento para a informação manipulada pelo programa. Portanto, uma parte muito importante do trabalho de desenvolvimento de softwares, além de saber utilizar linguagens de programação, também é ter noção da estrutura de dados, ramo de computação em que o acolamento e armazenamento de informações dos programas são estudados para, assim, terem suas execuções otimizadas.
Ou seja, ela é uma estrutura organizada de dados na memória de um computador ou em qualquer dispositivo de armazenamento (HD, RAM), de forma que os dados possam ser utilizados de forma correta. A alocação de memória é um aspecto crítico da programação de computadores, pois envolve a reserva e o gerenciamento de espaço na memória para armazenar dados e estruturas de dados. Existem vários métodos e técnicas para alocar memória em programas de computador, porém existem três tipos principais de alocação de memória: alocação estática, alocação automática e alocação dinâmica.
-
Alocação estática: ocorre quando são declaradas variáveis globais ou estáticas, que têm um tamanho fixo e estão organizadas sequencialmente na memória do computador. Essas variáveis mantêm seu valor durante toda a execução do programa, a menos que sejam modificadas explicitamente. Um exemplo de alocação estática é:
-
Alocação automática: ocorre quando são declaradas variáveis locais e parâmetros de funções, que são alocados na pilha de execução do programa (stack) a cada chamada da função, e liberados quando a função termina. Essas variáveis não preservam seu valor entre chamadas consecutivas da função. Um exemplo de alocação automática é:
-
Alocação dinâmica: ocorre quando o programa solicita explicitamente um bloco de memória para armazenar dados, usando funções como
malloc,callocourealloc. Esses blocos de memória não precisam ter um tamanho fixo nem estar organizados sequencialmente na memória, mas podem estar dispersos na área de heap. O programa é responsável por liberar as áreas alocadas dinamicamente, usando a função free. Um exemplo de alocação dinâmica é: -
Alocação de memória contígua: Podemos afirmar então que um programa é composto de algoritmos e estruturas de dados (DSA - Data Structure and Algorithms), que juntos fazem com que o programa funcione como deve. Eles podem ser isolados ou atuados em conjunto a fim de atender um problema específico. Portanto, é difícil falar de estruturas de dados sem usar algoritmos ou complexidade de algoritmos. Ou seja, uma estrutura de dados (ED), em ciência da computação, é uma coleção tanto de valores (e seus relacionamentos) quanto de operações (sobre os valores e estruturas decorrentes). É uma implementação concreta de um tipo abstrato de dado (TAD) ou um tipo de dado (TD): básico ou primitivo. Assim, o termo ED pode ser considerado sinônimo de TD, se considerado TAD um hipônimo de TD, isto é, se um TAD for um TD.
A Estrutura de Dados pode ser classificada em duas categorias. De acordo com essas categorias, podemos acessar ou gerenciar dados de acordo com nossa necessidade. Há várias maneiras de classificar a estrutura de dados:
- Estrutura de dados primitiva e não primitiva: A estrutura de dados que são atômicas (indivisíveis) são chamadas primitivas. Exemplos são
Int-Integer(inteiro),Float(reais) eChar-Character(personagens),Pointer(ponteiro/apontador). As estruturas de dados que não são atômicas são chamadas de não primitivas ou compostas. Exemplos são: registros, matriz, cadeia de caracteres, arrays, strings, files, stacks, queues, graphs e trees.
As estruturas de dados primitivas são tipos de dados básicos fornecidos diretamente pela linguagem de programação, e elas incluem tipos como inteiros, números de ponto flutuante, caracteres, booleanos e assim por diante. Elas são as unidades mais simples de dados com as quais você pode trabalhar em uma linguagem de programação.
-
Estruturas de dados lineares e não-lineares: Em uma estrutura de dados linear, os itens de dados são organizados em uma sequência linear. Por exemplo: matriz. Em uma estrutura de dados não linear, os itens de dados que não estão em sequência. Por exemplo: árvores e gráficos.
-
Estruturas de dados homogêneas e não homogêneas: Na estrutura de dados homogênea, todos os elementos são do mesmo tipo. Por exemplo: matrizes. Em uma estrutura de dados não homogênea, os elementos podem ou não ser do mesmo tipo. Por exemplo: registros.
-
Estruturas de dados estáticos e dinâmicos: Estruturas de dados estáticos são aquelas cujo tamanho/capacidade e estruturas de memória fixa, local associado é fixado em tempo de compilação. Estruturas dinâmicas são aquelas cujas que se expandem ou diminuem conforme necessário durante a execução do programa e associam a mudança de localização da memória.
Essas estruturas encontram muitas aplicações no desenvolvimento de sistemas, sendo que algumas são altamente especializadas e utilizadas no desenvolvimento de tarefas específicas. Usando as estruturas de dados adequadas através de algoritmos, podemos trabalhar com uma grande quantidade de dados, como aplicações em banco de dados e aplicações de busca.
Critérios para escolha e estudo de uma estrutura de dados incluem eficiência para buscas e padrões específicos de acesso, necessidades especiais para manejo de grandes volumes de dados (big data), ou a simplicidade de implementação e uso. Ou seja, os EDs eficientes são cruciais para a elaboração de algoritmos, diversas linguagens de programação possuem ênfase nas EDs, como evidenciado pela POO (ou OOP, paradigma de programação orientada a objetos), e aplicações distintas usufruem de ou requerem EDs específicas (um compilador usa uma tabela de dispersão para identificadores e namespaces, enquanto uma Árvore B ou Árvore AA é apropriada para acessos randômicos).
Em termos de EDs, os TDs e TADs são definidos indiretamente pelas operações e usos, e propriedades destas operações e usos: o custo computacional e o espaço que pode representar e ocupa na memória.
Na ciência da computação, uma ED é um modo particular de armazenamento e organização de dados em um computador de modo que possam ser usados eficientemente, facilitando sua busca e modificação. EDs e algoritmos são temas fundamentais da ciência da computação, sendo utilizados nas mais diversas áreas do conhecimento e com os mais diferentes propósitos de aplicação. Sabe-se que algoritmos manipulam dados. Quando estes dados estão organizados (dispostos) de forma coerente, caracterizam uma forma, uma estrutura de dados. A organização e os métodos para manipular essa estrutura é que lhe confere singularidade (e vantagens estratégicas, como a minimização do espaço ocupado na memória RAM), além (potencialmente) de tornar o código-fonte mais enxuto e simples.
Cada estrutura de dados tem um conjunto de métodos próprios para realizar operações como:
- Inserir ou excluir elementos;
- Buscar e localizar elementos;
- Ordenar (classificar) elementos de acordo com alguma ordem especificada.
E como falar de estrutura de dados sem algoritmos? Portanto, a disciplina “Algoritmos avançados” foi criada para combinar a teoria e a prática de algoritmos com base no paradigma de programação dinâmica e estrutura de dados. Muitas vezes a teoria de algoritmos e a prática de implementaçõoes eficientes é ensinado separadamente, em particular no caso de algoritmos avançados. Porém, a experiência mostra que encontramos muitos obstáculos no caminho de um algoritmo teoricamente eficiente para uma implementação eficiente. Além disso, o projeto de algoritmos novos não termina com uma implementação eficiente, mas é alimentado pelos resultados experimentais para produzir melhores algoritmos. O paradigma de programação dinâmica é uma técnica de resolução de problemas em ciência da computação e matemática que se baseia na quebra de um problema complexo em subproblemas menores e mais simples. A ideia fundamental por trás da programação dinâmica é resolver cada subproblema apenas uma vez e armazenar seu resultado para evitar o recálculo, economizando assim tempo de processamento. Isso é especialmente útil quando um problema pode ser decomposto em subproblemas sobrepostos ou recursivos.
Um subproblema no paradigma de programação dinâmica é uma parte menor do problema original que pode ser resolvida de forma independente e que pode contribuir para a solução geral. Um exemplo de um subproblema é o termo n da sequência de Fibonacci, que depende dos termos n-1 e n-2. Uma imagem de um subproblema no paradigma de programação dinâmica pode ser vista aqui, na página 4. Nessa imagem, o problema é encontrar o caminho mais curto entre dois vértices de um grafo, e os subproblemas são os caminhos mais curtos entre os vértices intermediários. A imagem mostra como a solução de cada subproblema é armazenada em uma tabela e como essa solução é usada para resolver os subproblemas maiores.
O processo típico de programação dinâmica envolve os seguintes passos:
-
Definição da estrutura do problema: Determine como o problema pode ser decomposto em subproblemas menores. Isso geralmente envolve identificar relações de recorrência entre os subproblemas e o problema original.
-
Resolução dos subproblemas: Resolva cada subproblema separadamente, idealmente apenas uma vez, e armazene seus resultados em uma tabela (geralmente uma matriz) para reutilização.
-
Combinação dos resultados dos subproblemas: Combine os resultados dos subproblemas para obter a solução final do problema original.
A programação dinâmica é frequentemente usada para resolver problemas de otimização, como encontrar a sequência mais longa com determinada propriedade, calcular o valor máximo ou mínimo de uma função sujeita a restrições, entre outros. Além disso, é uma técnica comum em algoritmos de processamento de sequências, como alinhamento de sequências de DNA, processamento de texto e muito mais.
Os algoritmos são a estrutura básica para a criação de soluções para problemas computacionais. A modularização de algoritmos é a principal forma para diminuir a complexidade desses problemas.
Os módulos ou subprogramas passam a tratar partes menores da complexidade do problema, facilitando a compreensão e futuras manutenções que serão necessárias durante o ciclo de vida de um software. A modularização também diminui o retrabalho, pois permite que trechos de códigos sejam reutilizados em outros locais no mesmo sistema.
Após a definição de um algoritmo, é necessário passar por uma otimização. Por mais que, atualmente, os computadores possuam uma capacidade computacional bastante poderosa, principalmente comparando com os recursos computacionais de décadas atrás, a otimização permite que o sistema possa ter um desempenho muito mais adequado, oferecendo ao usuário uma melhor experiência de uso.
A complexidade dos problemas cresceu tão rápido quanto a capacidade computacional, portanto é fundamental a capacidade de analisar diversos algoritmos para um problema complexo para se chegar ao algoritmo mais otimizado para o problema. Um algoritmo otimizado deverá executar em um menor espaço de tempo possível ocupando o menor espaço possível de memória.
Você verá a construção de algoritmos com suas respectivas estruturas de dados utilizadas, os conceitos de análise de algoritmos, explicando como analisar o pior caso de um algoritmo e se chegar a uma ordenação dos algoritmos para a solução de um determinado problema.
Segundo Forbellone e Eberspacher (2005), um problema matemático é tão mais complexo quanto maior for a quantidade de variáveis a serem tratadas, enquanto um problema algorítmico é tão mais complexo quanto maior for a quantidade de situações diferentes que precisam ser tratadas.
Um algoritmo é base de tudo que é programado para um computador e pode ser definido como uma sequência finita de etapas, perfeitamente definidas, que é utilizada para solucionar um problema.
Cada algoritmo tem uma complexidade que está intimamente associada à complexidade do problema a ser resolvida. Quanto maior for a variedade de situações a serem tratadas, maior será a complexidade.
A complexidade pode ser reduzida, reduzindo-se a variedade. E a variedade pode ser reduzida, dividindo problemas maiores em problemas menores. Os problemas menores são tratados através do emprego de sub-rotinas, que terão complexidade menor e poderão ser implementadas de uma forma mais fácil.
Uma técnica que será estudada para a decomposição de problemas é conhecida como top-down, a qual será estudada mais adiante, e que irá definir as sub-rotinas que devem ser criadas para a resolução dos problemas.
É recomendado utilizar a melhor linguagem de programação para seu aprendizado em estrutura de dados, pra ser mais específico, aquela que tem a sintaxe mais fácil de aprendizado, pois as estruturas podem impactar no seu aprendizado, recomendo utilizar linguagens de programação mais simples como javascript e Python, mas nada impede de você aprender com Java ou C++. Esse estudo fornece de forma severa os clássicos algoritmos avançados, programação dinâmica e estrutura de dados em Ciência da Computação, como também problemas extras que são constantemente usados em muitos desafios atuais e exigências de mercado.
In order to achieve greater coverage and encourage more people to contribute to the project, the algorithms are available in the following languages: C, C++, Java, Python, Go, Ruby, javascript, Swift, Rust, Scala e Kotlin.
| Data Structures |
|
|
|
|
|
|
|
|
|
|
|
| Binary Tree |
|
|
|
|
|
|
|
|
|
|
|
| Binary Search Tree |
|
|
|
|
|
|
|
|
|
|
|
| Double-ended Queue |
|
|
|
|
|
|
|
|
|
|
|
| Queue |
|
|
|
|
|
|
|
|
|
|
|
| Dynamic Queue |
|
|
|
|
|
|
|
|
|
|
|
| Graph |
|
|
|
|
|
|
|
|
|
|
|
| Circular Linked List |
|
|
|
|
|
|
|
|
|
|
|
| Singly Linked List |
|
|
|
|
|
|
|
|
|
|
|
| Doubly Linked List |
|
|
|
|
|
|
|
|
|
|
|
| Unordered Linked List |
|
|
|
|
|
|
|
|
|
|
|
| Sorted Linked List |
|
|
|
|
|
|
|
|
|
|
|
| Stack |
|
|
|
|
|
|
|
|
|
|
|
| Dynamic Stack |
|
|
|
|
|
|
|
|
|
|
|
| Ring Buffer |
|
|
|
|
|
|
|
|
|
|
|
| Hash Table |
|
|
|
|
|
|
|
|
|
|
|
| Sorting Algorithms |
|
|
|
|
|
|
|
|
|
|
|
| Bogosort |
|
|
|
|
|
|
|
|
|
|
|
| Bubble Sort |
|
|
|
|
|
|
|
|
|
|
|
| Bucket Sort |
|
|
|
|
|
|
|
|
|
|
|
| Cocktail Sort |
|
|
|
|
|
|
|
|
|
|
|
| Comb Sort |
|
|
|
|
|
|
|
|
|
|
|
| Counting Sort |
|
|
|
|
|
|
|
|
|
|
|
| Gnome Sort |
|
|
|
|
|
|
|
|
|
|
|
| Heapsort |
|
|
|
|
|
|
|
|
|
|
|
| Insertion Sort |
|
|
|
|
|
|
|
|
|
|
|
| Merge Sort |
|
|
|
|
|
|
|
|
|
|
|
| Quicksort |
|
|
|
|
|
|
|
|
|
|
|
| Radix Sort |
|
|
|
|
|
|
|
|
|
|
|
| Selection Sort |
|
|
|
|
|
|
|
|
|
|
|
| Shell Sort |
|
|
|
|
|
|
|
|
|
|
|
| Timsort |
|
|
|
|
|
|
|
|
|
|
|
| Extra |
|
|
|
|
|
|
|
|
|
|
|
| Queue using Stacks |
|
|
|
|
|
|
|
|
|
|
|
| Two-Sum Problem |
|
|
|
|
|
|
|
|
|
|
|
| Palindrome |
|
|
|
|
|
|
|
|
|
|
|
| Isogram |
|
|
|
|
|
|
|
|
|
|
|
| Leibniz Formula for Pi |
|
|
|
|
|
|
|
|
|
|
|
| Maze-Solving Algorithm |
|
|
|
|
|
|
|
|
|
|
|
| Rotten Oranges |
|
|
|
|
|
|
|
|
|
|
|
| Find Distinct Subsets |
|
|
|
|
|
|
|
|
|
|
|
Curiosidade: Foi feito um estudo Pareto para desempenho de algoritmos e gerou um percentual de Pareto, cujo 80% recursos - 20% do código consistia em Arquitetura de Software onde visa uma melhor implementação do modelo de software, Pareto^2 64% dos recursos - 7% do código consiste em Estrutura de Dados e Algoritmos visando o lado do desempenho, capacidade e estrutura do código, e Pareto^3 52% dos recursos - -1% do código para Micro Otimização.
A unidade central de processamento (UCP) ou central processing unit (CPU), também conhecida como processador, é a parte de um sistema computacional, que realiza as instruções de um programa de computador, que executar a aritmética básica, orientado por um padrão binário 0 e 1 que possibilita a entrada, o processamento e saída de dados. O papel da CPU pode ser comparado ao papel de um cérebro no funcionamento de um computador. Isto é, realiza operações lógicas, cálculos e processamento de dados. Seu circuito eletrônico executa instruções de um programa de computador, como aritmética, lógica, controle e operações de entrada/saída (E/S). Essa função contrasta com a de componentes externos, como memória principal e circuitos de E/S, e coprocessadores especializados, como unidades de processamento gráfico (GPUs).
O termo foi cunhado no início de 1960 e seu uso permanece até os dias atuais pois, ainda que sua forma, desenho e implementação tenham mudado drasticamente, seu funcionamento fundamental permanece o mesmo.
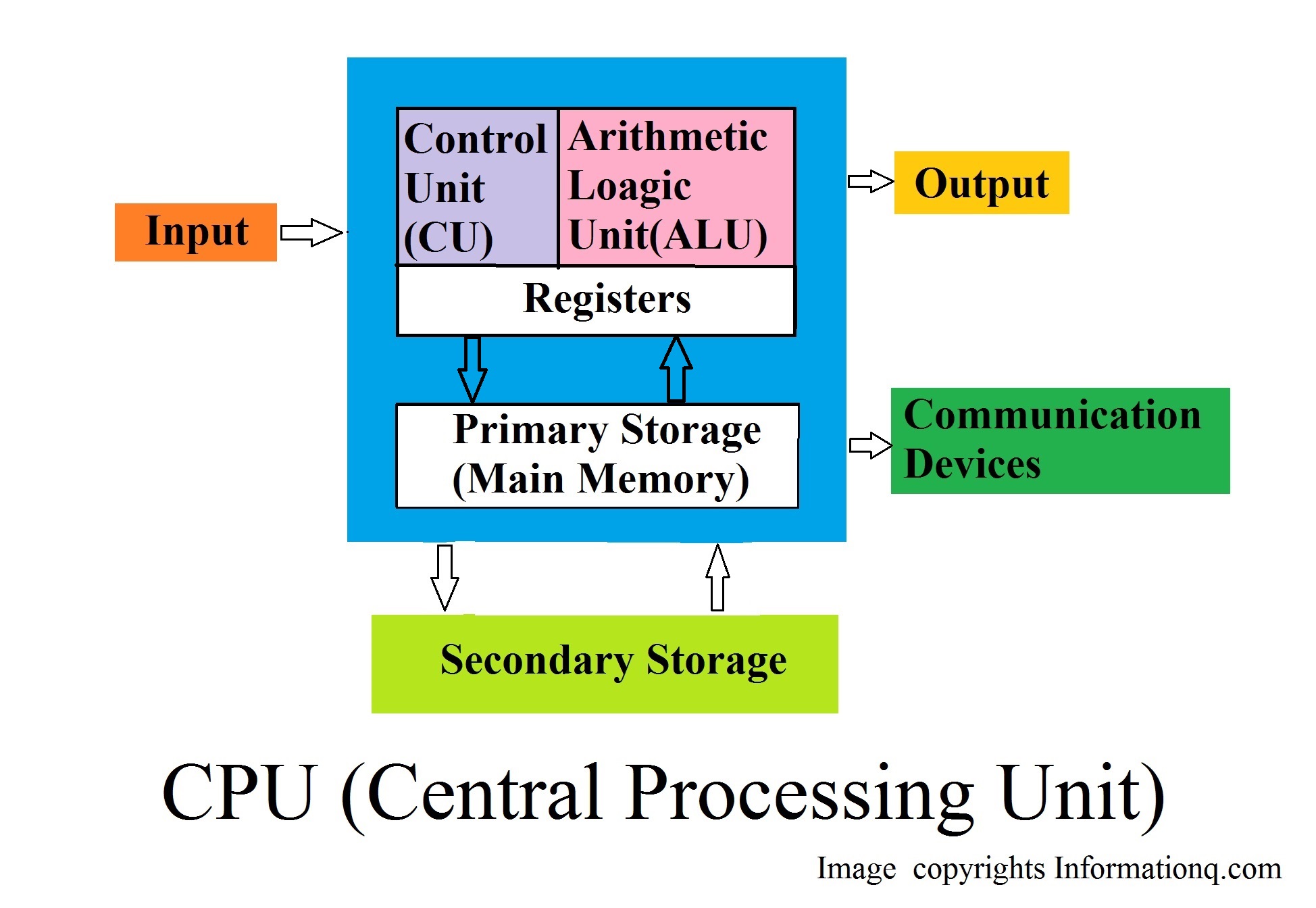
A forma, o design e a implementação das CPUs mudaram ao longo do tempo, mas sua operação fundamental permanece quase inalterada. Os principais componentes de uma CPU incluem a UC - Unidade de controle (CU - Control Unit) é responsável pela emissão de sinais de controle (gravação em disco ou busca de instrução na memória). A ULA - unidade aritmética-lógica (ALU - Arithmetic and Logic Unit) é responsável pela realização de operações lógicas (comparações) e aritméticas (somas e subtrações). Registradores de processador que fornecem operandos para a ALU e armazenam os resultados das operações da ALU e uma unidade de controle que orquestra a busca (da memória), decodificação e execução (de instruções) dirigindo as operações coordenadas da ALU, registradores e outros componentes. As CPUs modernas dedicam muita área de semicondutores a caches e paralelismo em nível de instrução para aumentar o desempenho e aos modos de CPU para suportar sistemas operacionais e virtualização.
A maioria das CPUs modernas é implementada em microprocessadores de circuito integrado (IC), com uma ou mais CPUs em um único chip IC. Os chips de microprocessador com várias CPUs são chamados de processadores multi-core. As CPUs físicas individuais, chamadas de núcleos de processador, também podem ser multithreaded para suportar multithreading no nível da CPU.

Um IC que contém uma CPU também pode conter memória, interfaces periféricas e outros componentes de um computador; esses dispositivos integrados são chamados de microcontroladores ou sistemas em um chip (SoC).
A velocidade da CPU é determinada pelo número de instruções que ela executa em uma unidade de tempo (não existe padronização).
MIPS (Milhões de instruções por segundo) é uma métrica usada para medir o desempenho de uma CPU. Ela indica quantas milhões de instruções a unidade de processamento consegue executar em um segundo. Por exemplo, se um processador executa 10 milhões de instruções em um segundo, ele tem desempenho de 10 MIPS.
No entanto, essa métrica tem limitações. O MIPS não leva em conta a complexidade das instruções, o tipo de tarefa executada ou a eficiência do sistema de memória. Por isso, dois processadores com o mesmo valor de MIPS podem ter desempenhos muito diferentes em aplicações reais.

Hoje em dia, benchmarks mais sofisticados, como o SPECint ou o uso de FLOPS (operações de ponto flutuante por segundo), são preferidos para avaliar o desempenho real de sistemas.
Estrutura interna de um processador (PEPE-8): A estrutura interna de um processador como o PEPE-8 (um processador educacional amplamente usado para fins didáticos) é modelada com base em conceitos de portas lógicas e circuitos digitais. Isso permite que estudantes compreendam como funciona a execução de instruções em nível de hardware.
O PEPE-8 é um processador didático que simula uma arquitetura baseada no modelo de Von Neumann. Ele é frequentemente representado em diagramas que incluem unidades funcionais, barramentos, registradores e caminhos de controle. Esses componentes são construídos logicamente por meio de portas digitais (AND, OR, NOT, XOR, etc.) e flip-flops.

Inicialmente os SOs eram monotarefa, ou seja, apenas uma tarefa (programa) era executada de cada vez. Com a evolução dos sistemas computacionais, os SOs também evoluíram no sentido de dar suporte à execução de várias tarefas ao mesmo tempo, de forma real em sistemas com múltiplos processadores, ou de forma concorrente em sistemas com único processador, por meio de multiprogramação.
O processo é cada atividade de um SO que consiste na execução de um ou mais programas que são chamados toda vez que a respectiva função é requirida. O processo é gerado pelo compilador, é um conceito dinâmico e os processos concorrem pelo processo. Assim, um processo pode ser considerado como sendo a sequência de ações realizadas pela execução de instruções cujo resultado final fornece uma das funções do sistema.
Esse conceito pode ser estendido de forma que inclua as funções do usuário. Então, a execução de um programa de um usuário é também um processo. Um processo pode envolver a execução de mais de um programa e, por outro lado, um mesmo programa pode ser requirido por mais de um processo.
O conceito de processo é dinâmico, já o de programa é estático. Por exemplo, uma rotina que inclui um nó numa lista, pode ser usada por qualquer um dos processos encarregados pela manipulação da lista. O fato de sabermos que a rotina está ativa, em certo instante, não é suficiente para que se saiba qual das funções do sistema está sendo realizada.
Na realização das funções de um SO, algumas vezes é conveniente forçar o paralelismo de algumas atividades. As razões para o paralelismo são:
-
Disponibilidade de agentes (para levar a cabo a atividade);
-
Reduzir o tempo de execução da tarefa.
Nem sempre é possível usar paralelismo, uma vez que o início de um processo pode estar condicionado à conclusão de outro (ou outros). Por exemplo:
Processos progridem graças à intervenção de um agente que executa o(s) programa(s) correspondente(s). Esse agente é o processador.
Estados do processo são feitos de forma síncrona, ao longo de seu tempo de vida, um processo vai assumindo vários estados que representam sua situação atual. Quando um processo muda de estado dizemos que ele sofreu uma transição.
Estados do processo em sistemas monotarefas, este tipo de sistema, cada programa é carregado do disco para a memória e executado até sua conclusão. Os dados são carregados na memória juntamente com o código executável, e os resultados obtidos no processamento salvos no disco após a conclusão da tarefa.
Onde:
-
Novo: O processo está sendo criado, o código e os dados necessários para sua execução estão sendo carregados na memória.
-
Executando: As instruções do programa estão sendo executadas no processador.
-
Terminando: O programa foi totalmente processado, produziu os resultados e pode ser removido da mémoria do sistema.
Estados do processo em sistemas multitarefas, neste tipo de sistema, vários programas podem ser executados ao mesmo tempo.
Como vimos sobre Paralelismo, existe também o termo "pseudo-paralelismo" que é quando os programas apenas parecem ser executados ao mesmo tempo, cada um em processador ou core diferente.
O diagrama de transições mostra os diferentes estados possíveis de um processo, além do agente que causa a mudança de estado.
-
Novo: O processo está sendo criado, o código e os dados necessários para sua execução estão sendo carregados na memória, e as estruturas de dados do núcleo estão sendo atualizadas para permitir o controle de sua execução. Após o término de sua criação, ele passa ao estado de pronto.
-
Pronto: O processo é colocado em uma fila de prontos, ou seja, ele está preparado para executar (ou para continuar sua execução), apenas aguardando a disponibilidade do processador. O algoritmo de Escalonamento escolhe um processo para "ganhar" a CPU, passando este, então, ao estado de executando. Na fila de prontos, os processos que são organizados em uma fila para serem escalonados, ou seja, colocados em execução. A ordem de execução é determinada por algoritmos de gerencia de CPU. Continuar sua execução é além dos processos que estão na fila, por terem sido criados (Novo) os processos que estavam bloqueados, esperando um dado ou evento, e os que estavam executando e sofreram preempção, voltam à fila de prontos para serem novamente escalonados, visando continuar a execução do ponto onde pararam.
-
Executando: As instruções do programa estão sendo executadas no processador. A partir deste estado, três transições podem ocorrer: O processo solicita uma operação de E/S, o processo passa a bloqueado; O processo chegou ao seu final ou ocorreu um erro que o impede de prosseguir - passa ao estado de terminado. Ocorre uma interrupção - processo passa ao estado de pronto.
3.2 Interrupção: Evento externo que faz o processador parar a execução do programa corrente e desviar a execução para um bloco de código chamado rotina de interrupção. Normalmente, são decorrentes de operações de E/S ou do relógio do sistema.
-
Bloqueado: O processo não pode ser executado porque depende de dados externos ainda não disponíveis (do disco ou da rede, por exemplo) necessitando de uma operação de entrada/saída ou aguarda algum tipo de evento ocorrer. Ao terminar a operação E/S ou ocorrendo o evento aguardado, o processo passa ao estado de pronto.
-
Terminado: O programa foi totalmente processado, produziu os resultados e pode ser removido da memória do sistema e as estruturas de controle podem ser apagadas.
BCP - Bloco de controle de processo os programas do interior do núcleo são responsáveis pela manutenção do meio ambiente onde os processos existem. Portanto, esses programas devem operar sobre estruturas de dados que correspondam à representação física de todos os processos do sistema. Cada processo é representado por um descritor (bloco de controle ou BCP), que é uma área de memória contendo todas as informações relevantes do processo. Veja, a seguir, um exemplo de BCP:
No BCP, controlamos uma série de dados incluindo:
-
Informações de escalonamento de CPU: incluem prioridade de processo, ponteiros para filas de escalonamento e quaisquer outros parâmetros de escalonamento.
-
Estado do processo: pronto, executando ou bloqueado.
-
Número do processo: constitui o seu identificador dentro do Sistema Operacional.
-
Contador do processo: indica o endereço da próxima instrução a ser executada para esse processo.
-
Registradores de CPU: correspondem ao conteúdo dos registradores da CPU no momento em que o programa saiu do estado de executando para bloqueado ou pronto. Juntamente com o contador do programa, essas informações de estado devem ser salvas para permitir que o processo continue corretamente depois.
-
Informações de gerência de memória: podem incluir dados como o valor dos registradores de base e limite, as tabelas de páginas ou tabelas de segmentos, dependendo do sistema de memória usado pelo sistema operacional.
-
Informações de contabilização: incluem a quantidade de CPU e o tempo real usados, limites de tempo, números de contas, números de jobs, ou processos, etc.
-
Informações de status de E/S: incluem a lista de dispositivos de E/S alocados para este processo, uma lista de arquivos abertos e outras informações.
As informações do BCP podem ser agrupados em contexto de hardware e em contexto de software do processo, isto é, informações que precisam ser salvas quando o processo perde o controle de um processador, de maneira a possibilitar o reinicio da execução quando o processo passar novamente a executar.
-
Contexto de Hardware: é constituído basicamente dos valores dos registradores/ flags da máquina antes do bloqueio.
-
Contexto de Software: é constituído da identificação do processo, seus limites em termos de recursos (número máximo de arquivos, tamanho de memória permitido, número de subprocessos, permitidos, etc.) e nível hierárquico do processo (que determina o que o processo pode ou não fazer em termos de operações protegidos do sistema).
Os estados dos processos incluem ainda novo e terminado. Porém, estes estados não são representados no BCP, pois não correspondem a processos ativos. No caso de novo o BCP está sendo criado, e no de terminado, sendo destruído.
Troca de contexto: Quando ocorre a preempção ou um processo solicita E/S um novo processo é escalonado. Para que o processo interrompido possa voltar a ser executado corretamente no futuro, o seu contexto deve ser salvo no BCP, e o novo processo e o que irá iniciar a execução, ter o seu contexto lido no BCP.
A estas tarefas denominamos troca de contexto conforme exemplificado a seguir:
Criação de processos: Um processo, durante sua execução, pode ativar outros processos através de uma chamada de sistema (System calls) para criar o que chamamos de processos filhos, formando uma árvore de processos com o conceito de herança, podemos ver abaixo:
Esses processos têm as mesmas prerrogativas do processo pai, possuindo espaço de endereçamento e contextos de hardware e software. Para gerenciar esses processos, o SO filho adota os mesmos critérios que para os processos pais.
Os processos podem ser classificados de acordo com o tipo de processamento que realizam, a saber:
-
CPU-bound (ligado à CPU): Passa a maior parte do tempo no estado de execução, ou seja, utilizando o processador. Esse tipo de processo realiza poucas operações de E/S;
-
I/O-bound (ligado à E/S): Passa a maior parte do tempo no estado bloqueado, pois realiza um elevado número de operações de E/S;
Para entender melhor essa questão, vamos primeiro analisar o que é um programa. Um programa é um arquivo executável que contém um conjunto de instruções e é armazenado passivamente em disco. Um programa pode ter múltiplos processos. Por exemplo, o navegador Chrome cria um processo diferente para cada aba.
Um processo significa que um programa está em execução. Quando um programa é carregado na memória e se torna ativo, ele se transforma em um processo. O processo requer alguns recursos essenciais, como registradores, contador de programa e pilha.
Uma thread é a menor unidade de execução dentro de um processo.
O processo a seguir explica a relação entre programa, processo e thread.
O programa contém um conjunto de instruções.
O programa é carregado na memória. Ele se torna um ou mais processos em execução.
Quando um processo é iniciado, ele recebe memória e recursos. Um processo pode ter uma ou mais threads. Por exemplo, no aplicativo Microsoft Word, uma thread pode ser responsável pela verificação ortográfica e outra pela inserção de texto no documento.
Principais diferenças entre processos e threads:
Processos geralmente são independentes, enquanto threads existem como subconjuntos de um processo.
Cada processo tem seu próprio espaço de memória. Threads que pertencem ao mesmo processo compartilham a mesma memória.
Um processo é uma operação complexa. Leva mais tempo para ser criado e finalizado.
A troca de contexto entre processos é mais custosa.
A comunicação entre threads é mais rápida.
Note
Agora é com você: Algumas linguagens de programação suportam corrotinas. Qual a diferença entre corrotina e thread? Como listar os processos em execução no Linux?
VHDL é uma linguagem de descrição de hardware cujo nome vem de VHSIC Hardware Description Language, sendo VHSIC a sigla para Very High Speed Integrated Circuit, um programa do Departamento de Defesa dos Estados Unidos que impulsionou sua criação na década de 1980. Diferente de linguagens como C, Java ou Python, que são usadas para programar software executado sequencialmente por um processador, o VHDL é utilizado para descrever o comportamento e a estrutura de circuitos digitais, permitindo que engenheiros projetem sistemas eletrônicos complexos como processadores, controladores, interfaces de comunicação e dispositivos lógicos programáveis.
A principal característica do VHDL é que ele descreve hardware, não algoritmos sequenciais tradicionais. Em vez de pensar em uma sequência de instruções que rodam uma após a outra, o projetista pensa em sinais, portas lógicas, registradores, estados e conexões que operam de forma concorrente. Isso significa que múltiplas partes do sistema descrito em VHDL podem funcionar ao mesmo tempo, refletindo a natureza paralela dos circuitos digitais reais. O código em VHDL pode representar desde um simples flip-flop até a arquitetura completa de um microprocessador, incluindo unidades aritméticas, controladores de memória e barramentos internos.
O VHDL permite descrever hardware em diferentes níveis de abstração. No nível comportamental, o projetista descreve o que o sistema deve fazer, sem necessariamente especificar como cada porta lógica está conectada. No nível estrutural, ele define explicitamente os componentes e como eles se interligam, quase como desenhar o esquema elétrico em forma textual. Há também o nível de transferência de registradores, conhecido como RTL (Register Transfer Level), que é amplamente utilizado na indústria por equilibrar clareza e controle sobre a implementação física do circuito. A partir dessa descrição, ferramentas de síntese convertem o código VHDL em uma representação física que pode ser implementada em FPGAs ou transformada em máscaras para fabricação de chips ASIC.
Além de servir para síntese, o VHDL é muito utilizado para simulação. Antes de fabricar um circuito, os engenheiros podem testar seu comportamento em ambiente virtual, verificando se a lógica funciona corretamente sob diferentes condições. Isso reduz custos e evita erros críticos no hardware final. A linguagem inclui mecanismos específicos para modelar temporização, eventos, sinais concorrentes e estados finitos, todos essenciais para representar corretamente o funcionamento de sistemas digitais.
Em termos conceituais, o VHDL representa uma ponte entre o mundo da engenharia eletrônica e o da programação. Ele permite que circuitos sejam projetados de maneira abstrata, textual e versionável, assim como software, mas com o objetivo final de gerar hardware físico. Isso o diferencia profundamente de linguagens tradicionais, pois o resultado final não é um programa executável em um sistema operacional, mas sim um circuito eletrônico que passa a existir fisicamente dentro de um chip. Dessa forma, o VHDL é uma ferramenta fundamental no desenvolvimento de sistemas embarcados, dispositivos de telecomunicações, controladores industriais e praticamente qualquer tecnologia moderna que dependa de lógica digital personalizada.
Naturalmente, que a gerência necessária sempre que se muda o estado de um processo, é onerosa (em termos de tempo) e indesejável do ponto de vista da melhoria de performance do sistema.
Para contornar esse problema e diminuir o custo de manipulação de processos, instituiu-se outra unidade chamada thread, que não possui todas as prerrogativas de um processo, mas também permite algum tipo de paralelismo das funções.
Thread (em português: fio de execução ou encadeamento de execução) é uma forma como um processo/tarefa de um programa de computador é divido em duas ou mais tarefas que podem ser executadas concorrentemente ("simultâneo"). O suporte à thread é fornecido pelo sistema operacional no caso da linha de execução ao nível do núcleo (em inglês: Kernel-Level Thread, KLT), ou implementada através de uma biblioteca de uma determinada linguagem de programação (User-Level Thread, ULT). Uma thread permite, por exemplo, que o utilizador de um programa utilize uma funcionalidade do ambiente enquanto outras linhas de execução realizam outros cálculos e operações.
Em equipamentos (hardwares) que possuem apenas uma única CPU, cada thread é processada de forma aparentemente simultânea, pois a mudança entre uma thread e outra é feita de forma tão rápida que para o utilizador, isso está acontecendo concorrentemente. Em equipamentos com múltiplos CPUs (também chamados multi-cores), as threads são realizadas realmente de forma simultânea.
Os sistemas que suportam uma única thread (em real execução) são chamados de single-thread enquanto que os sistemas que suportam múltiplas threads são chamados de multithread (multitarefa).
Thread (linha de execução) é uma sequência de instruções que faz parte de um processo principal. Um software é organizado em processos. Cada processo é dividido em threads, que formam tarefas independentes, mas relacionadas entre si. CPUs podem realizar multithreading simultâneo (SMT) para ter mais desempenho.
Threads são fluxos de execução (linha de controle) que rodam dentro de um processo. Em processos tradicionais, há uma única linha de controle e um único contador de programa. Porém, alguns sistemas operacionais fornecem suporte para múltiplas linhas de controle dentro de um processo (sistema multi-thread).
De fato, um processo pode ser constituído de várias threads, cada uma concorrendo de forma independente pelo uso da CPU. Para tanto, elas podem ter diferentes prioridades e contextos de hardware. Entretanto, compartilham todas o mesmo espaço de endereçamento e o mesmo contexto de software (que são características do processo).
Compare, abaixo, os dois tipos:
🧵 Processo com uma única thread (single-thread process) é aquele que possui apenas uma linha de execução. Isso significa que ele executa uma tarefa por vez, de forma sequencial. Toda a lógica do programa depende dessa única thread — se ela estiver esperando por uma operação de entrada/saída (como ler um arquivo), o processo inteiro fica parado até que essa operação termine.
Exemplo: Um editor de texto simples que só responde ao teclado depois de terminar de carregar um arquivo.
🧶 Processo com múltiplas threads (multithread process) possui várias threads de execução dentro do mesmo espaço de memória. Essas threads compartilham recursos como variáveis globais, arquivos abertos e memória alocada, mas cada uma tem sua própria pilha de execução.
Isso permite que diferentes partes do programa sejam executadas simultaneamente (ou quase isso, dependendo do número de núcleos da CPU). É ideal para tarefas que podem ser divididas, como:
- Um navegador com uma thread para a interface, outra para carregar páginas e outra para executar scripts.
- Um servidor web que atende múltiplos clientes ao mesmo tempo.
Comparando os dois:
| Característica | Processo com uma thread | Processo com múltiplas threads |
|---|---|---|
| Execução simultânea | Não | Sim (em paralelo ou concorrente) |
| Compartilhamento de dados | Não aplicável | Sim, entre threads do mesmo processo |
| Complexidade de programação | Baixa | Alta (exige controle de concorrência) |
| Eficiência em CPUs modernas | Limitada | Alta, especialmente em sistemas multicore |
Um exemplo tradicional do uso de multiplas threads seria um navegador web (browser), no qual pode ter uma thread para exigir imagens ou texto enquanto outro thread recupera dados de uma rede.
Benefícios do uso de thread:
-
Capacidade de resposta: Ao se utilizar várias threads, em uma aplicação interativa, podemos permitir que parte de um programa continue executando, como, por exemplo, a interface do usuário, enquanto outra parte esteja bloqueada, realizando, por exemplo, uma operação de entrada/saída.
-
Compartilhamento de recursos: As threads compartilham o código, os dados e os arquivos do processo ao qual pertencem, o que permite que uma aplicação possua várias threads de atividades dentro do mesmo espaço de endereçamento.
-
Economia: A alocação de memória e recursos para a criação de processos é dispendiosa. Como as threads compartilham estes recursos do processo, é muito mais rápido criá-las e permitar seus contextos.
-
Escalabilidade: Em sistemas multiprocessados, a utilização de threads permite que várias atividades, do mesmo processo, sejam realizadas em paralelo nos diversos núcleos.
Vejamos um exemplo de uso de thread: Um programa servidor, como por exemplo, o servidor Web Apache obtém um enorme benefício como o uso de threads, pois ao invés de criar um novo processo para atender às requisições de usuários, pode criar threads: Arquitetura do servidor multi-thread
-
Solicitação: O cliente faz uma nova requisição, no caso, o browser solicita uma nova página.
-
Cria novo thread para atender a solicitação: O processo servidor solicita a criação de uma nova thread que ficará responsável por atender a esta solicitação.
-
Volta a escutar solicitações adicionais do cliente: O processo servidor fica disponível para atender as novas solicitações de clientes, enquanto a thread criada, no passo dois, continua a trabalhar na solicitação anterior.
Como vimos, processo é um programa em execução, mas qual a diferença entre o processo de uma aplicação, como o Word, para o servidor de um banco de dados como o Oracle?
Existem dois conceitos diferentes, uma aplicação é um programa que você chama para executar, ele cria um processo e fica ativo até você o fechar.
Um serviço é um programa que fica executando em segundo plano, normalmente para oferecer alguma funcionalidade de servidor. Podemos ter uma noção do consumo de processos e mais sobre serviços abrindo o gerenciador de tarefas do Windows. O percentual listado em utilização da CPU representa a ocupação no último minuto. Quando, em execução, o processo utiliza toda a capacidade do processador. Para acessar os serviços pode:
- Gerenciador de tarefas > Serviços
- Painel de controle > Ferramentas administrativas > Serviços
- Menu iniciar > Serviços
Ao selecionar em um serviço aparecerá as opções de parar, pausar ou reinicializar o serviço se ele estiver em execução. Esse serviço pode ser iniciado automaticamente ou manualmente pelo SO.
-
Automático = inicializado durante o boot do sistema (dependendo do serviço pode não ser recomendado, pois ele consome recursos do SO)
-
Manual = inicializado pelo usuário.
Warning
Essa parte de troca de inicialização pode ser delicada e, dependendo do caso, pode causar vários erros. Portanto tome cuidado!
A parte do SO responsável por realizar a seleção do processo a ser executado é o escalonador, que distribui o uso da CPU entre os vários processos prontos. Para determinar a ordem com que os processos serão executados, o escalonador utiliza créditos definidos por um determinado algoritmo ou política de escalonamento de processos.
O gerenciador de processos é a parte de um SO em que são definidos a ordem e os critérios para executar os processos em uma máquina.
O procedimento de determinar qual processo será executado, por quanto tempo, em que ordem, dentre os diversos processos que estejam na fila de prontos é chamado escalonamento, podendo ser:
-
Preemptivo: Um tarefa pode perder o processador caso termine seu quantum de tempo, execute uma chamada de sistema ou caso ocorra uma interrupção que acorde uma tarefa prioritária (que estava suspensa aguardando um evento). A cada interrupção, exceção ou chamada de sistema, o escalonador pode reavaliar todas as tarefas da fila de prontas e decidir se mantém ou substitui a tarefa atualmente em execução.
-
Não preemptivo: Também chamado de cooperativo: a tarefa em execução permanece no processador tanto quanto possível, só abandonando-o caso termine de executar, solicite uma operação de E/S ou libere explicitamente o processador, voltando à fila de tarefas prontas. Esses sistemas são chamados de cooperativos por exigir a cooperação das tarefas entre si na gestão do processador, para que todas possam executar.
-
Quantum: É o tempo máximo que um processo pode executar a cada vez que passa ao estado de executando. Após esse tempo ele é interrompido e colocado no fim da fila de prontos.
Na maioria dos SO, de uso geral atuais, é preemptiva. Sistemas mais antigos, como o Windows 3, PalmOS 3 e MacOS 8 e 9 operavam de forma cooperativa.
Pergunta popular em entrevista: Qual é a diferença entre Processo e Thread?
Para entender melhor essa questão, vamos primeiro analisar o que é um Programa. Um Programa é um arquivo executável contendo um conjunto de instruções e armazenado passivamente no disco. Um programa pode ter múltiplos processos. Por exemplo, o navegador Chrome cria um processo diferente para cada aba.
Um Processo significa que um programa está em execução. Quando um programa é carregado na memória e se torna ativo, o programa se torna um processo. O processo requer alguns recursos essenciais, como registradores, contador de programas e pilha.
Uma Thread é a menor unidade de execução dentro de um processo.
O processo a seguir explica a relação entre programa, processo e thread.
O programa contém um conjunto de instruções.
O programa é carregado na memória. Ele se torna um ou mais processos em execução.
Quando um processo começa, ele recebe memória e recursos. Um processo pode ter uma ou mais threads. Por exemplo, no aplicativo do Microsoft Word, um tópico pode ser responsável pela correção ortográfica e o outro tópico por inserir texto no documento.
Principais diferenças entre processo e thread:
Processos geralmente são independentes, enquanto threads existem como subconjuntos de um processo.
Cada processo possui seu próprio espaço de memória. Threads que pertencem ao mesmo processo compartilham a mesma memória.
Um processo é uma operação pesada. Leva mais tempo para criar e terminar.
A troca de contexto é mais cara entre processos.
A comunicação entre threads é mais rápida para threads.
Deixando a palavra para você:
- Algumas linguagens de programação suportam corrotinas. Qual é a diferença entre corrotina e fio?
- Como listar processos em execução no Linux?
A gerência do processador é uma das funções principais de um sistema operacional. Ela é responsável por gerenciar a execução de processos e threads (ou subprocessos) em um sistema computacional. É um ponto decisivo, no desenvolvimento de um sistema operacional, é como alocar de forma eficiente o processador (CPU) para os vários processos prontos para serem executados.
Os principais objetivos da gerência do processador são:
- Multiprogramação: Permitir que vários processos sejam executados simultaneamente no sistema.
- Multiprocessamento: Aproveitar a capacidade de processamento de múltiplos processadores ou núcleos de processamento.
- Gerenciamento de recursos: Gerenciar os recursos do sistema, como tempo de processador, memória e dispositivos de entrada e saída.
- Priorização de processos: Priorizar a execução de processos com base em critérios como prioridade, tempo de resposta e uso de recursos.
As principais funções da gerência do processador incluem:
- Criação e término de processos: Criar e terminar processos em resposta a solicitações do usuário ou de outros processos.
- Escalonamento de processos: Selecionar o próximo processo a ser executado com base em critérios de priorização.
- Contexto de processo: Salvar e restaurar o estado de um processo quando ele é interrompido ou retomado.
- Gerenciamento de threads: Gerenciar a execução de threads dentro de um processo.
Existem vários algoritmos de escalonamento que podem ser usados para gerenciar a execução de processos, incluindo:
- FCFS (First-Come-First-Served): Executar os processos na ordem em que eles chegam.
- SJF (Shortest Job First): Executar o processo com o tempo de execução mais curto primeiro.
- RR (Round Robin): Executar cada processo por um tempo fixo (chamado de "fatia de tempo") antes de passar para o próximo processo.
- Prioridade: Executar os processos com base em sua prioridade.
Ciclo de vida de um processo:
Tipos de ciclo: A execução de um processo é uma sucessão de ciclos de execução de instruções (CPU burst) e espera pelo término da operação de entrada e saída (E/S burst).
A execução começa com um CPU burst, seguido de um E/S burst e novamente um CPU burst.
Critérios de escalonamento são para a avaliação dos algoritmos de escalonamento (scaling).
-
Justiça: O algoritmo de escalonamento deve ser justo com todos os processos, onde cada um deve ter uma chance de usar o processador.
-
Utilização da CPU: Mede o percentual de uso, que deve ser o maior possível.
-
Through put: número de processos que foram complementados por unidade de tempo.
-
Tempo turn around: É a soma dos tempos gastos, pelo processo esperando para obter a CPU (fila de prontos), esperando por memória, executando na CPU e esperando por E/S.
-
Tempo de espera: soma dos períodos de tempos gastos esperando na fila de prontos.
-
Tempo de resposta: tempo decorrido entre a sub-missão de um processo até que a primeira resposta seja obtida. Não é considerado o tempo gasto com a efetiva saída do pedido, uma vez que este depende da velocidade do dispositivo de saída.
As políticas de escalonamento não preemptivas:
Escalonamento First Come First Served (FCFS) trata-se do algoritmo de escalonamento de implementação mais simples. Com este algoritmo de escalonamento, o primeiro processo que solicita a CPU é o primeiro a ser alocado. Dessa forma, os processos que estão prontos para serem executados pela CPU são organizados em uma fila, que funciona baseada na política FIFO - First in First out, ou seja, o primeiro a entrar é o primeiro a sair.
Vejamos um exemplo, considere o seguinte conjunto de processos:
| Processo | Tempo de chegada | Tempo de serviço/execução |
|---|---|---|
| A | 0 | 3 |
| B | 2 | 6 |
| C | 4 | 4 |
| D | 6 | 5 |
| E | 8 | 2 |
Supondo que a ordem de chegada dos processos seja (A-B-C-D-E) utilizando FCFS, a ordem de execução dos processos mostrada a seguir: Diagrama de tempo usando a política FCFS:
[0] -> Para este conjunto de tarefas, o tempo de espera do processo A é de 0 (zero) unidades de tempo.
[3] -> Para o processo B de 3 unidades de tempo.
[9] -> Para o processo C de 9 unidades de tempo.
[13] -> Para o processo D de 13 unidades de tempo.
[18] -> Para o processo E de 18 unidades de tempo.
[20] -> Para este conjunto de tarefas, o tempo de final do processo E é de 20 unidades de tempo.
O tempo médio de espera na fila de prontos é de (0 + 12 + 20 + 35) / 4, que equivale a 16,75 unidades de tempo.
Nesta política de escalonamento, o tempo médio de espera é, com frequência, um tanto longo. Outro ponto é que processos importantes podem ser obrigados a esperar devido à execução de outros processos menos importantes dado que o escalonamento FCFS não considera qualquer mecanismo de distinção entre processos.
Como vimos, a fila de execução funciona baseada na política FIFO. Veja, a seguir, como essa política funciona:
Passo 1: A fila de prontos é organizada pelo tamanho de processos, do menor para o maior: P3, P1 e P2.
Passo 2: O processo P3, primeiro da fila de prontos, é colocado em execução e a fila de prontos é reorganizada.
Passo 3: O processo P3 executa por 3 unidades de tempo.
Passo 4: O processo P3 é movido pelo SO para "Terminado".
Passo 5: O processo P1, primeiro da fila de prontos, é colocado em execução e a fila de prontos é reorganizada.
Passo 6: O processo P1 executa por 5 unidades de tempo.
Passo 7: O processo P1 é movido pelo SO para "Terminado".
Passo 8: O processo P2, primeiro da fila de prontos, é colocado em execução e a fila de prontos reorganizada.
Passo 9: O processo P2 executa por 12 unidades de tempo.
Passo 10: O processo P2 é movido pelo SO para "Terminado".
Passo 11: A fila prontos está vazia, não existe processos para escalonar.
Existe uma variante preemptiva deste algoritmo onde o escalonamento é realizado não com base no tempo total de execução do processo, mas no tempo previsto para a duração de seu próximo CPU burst.
As políticas de escalonamento preemptivas:
Escalonamento por prioridade a cada processo é associada um prioridade e a CPU é alocada para o processo com a mais alta prioridade. Processos com prioridades iguais são escalados segundo a política FCFS. Para facilitar a compreensão, veja o exemplo a seguir:
Considere o seguinte conjunto de processos:
| Processor | Prioridade | Duração de execução |
|---|---|---|
| A | 2 | 10 |
| B | 4 | 8 |
| C | 3 | 6 |
| D | 1 | 4 |
Dessa forma, baseado na política de escalonamento por prioridades (quanto menor o número, maior a prioridade), a ordem de execução dos processos é mostrado a seguir:
Diagrama de tempo usando a política SJF:
A prioridade de um processo pode ser de dois tipos:
-
Prioridade estática: não muda durante a vida do processo.
-
Prioridade dinâmica: prioridade ajustada de acordo com o tipo de processamento e/ou carga do sistema.
Veja um exemplo: Ordem de processos diferente da anterior
Passo 1: A fila de prontos é organizada na ordem de prioridade dos processos. Primeiro P2, que tem prioridade 5 e depois P1 e P3, ambos com prioridade 3, sendo que P1 chegou antes (FIFO).
Passo 2: O processo P2, primeiro da fila de prontos, é colocado em execução e a fila de prontos é reorganizada.
Passo 3: O processo P2 executa por 3 unidades de tempo.
Passo 4: O processo P2 é movido pelo SO para "Terminado".
Passo 5: O processo P1, é o primeiro da fila de prontos, é colocado em execução e a fila de prontos é reorganizado.
Passo 6: O processo P1 é movido pelo SO para "terminado".
Passo 7: O processo P3, primeiro processo da fila de prontos, é colocado em execução e a fila de prontos é reorganizada.
Passo 8: O processo P3 executa por 12 unidades de tempo.
Passo 10: O processo P3 é movido pelo SO para "Terminado".
Passo 11: A fila de prontos está vazia, não existe processos para escalonar.
Este escalonamento pode ser tanto preemptivo quanto não preemptivo. O maior problema deste escalonamento é o Starvation (processo de baixa prioridade ser indefinidamente postergado). Um método para previnir starvation é o aging que consiste em ir aumentando gradualmente a prioridade de um processo, à medida que ele fica esperando.
Escalonamento RR - Round Robin (circular) especialmente útil para sistemas de tempo compartilhado, permite a implementação da multiprogramação em sistemas monoprocessados. Cada processo ganha um tempo limite para sua execução. Após esse tempo ele é interrompido e colocado no fim da fila de prontos. Este tempo é chamado de fatia de tempo (time-slice ou quantum). Geralmente, se situa entre 100 e 300ms.
Assim, um processo executa durante um quantum específico. Se o quantum for suficiente para este processo finalizar, outro processo do início da fila é selecionado para executar. Se durante sua execução o processo bloquear (antes do término do quantum), outro processo da fila de prontos também é selecionado.
Se terminar a fatia de tempo do processo e ele estiver em execução, o mesmo é retirado do processador, que é disponível para outro processo.
Veja o próximo exemplo:
| Processo | Tempo de serviço/execução |
|---|---|
| A | 12 |
| B | 8 |
| C | 15 |
| D | 5 |
É o mesmo conjunto de tarefas utilizado no exemplo de FCFS. Para escalonar este conjunto de tarefas utilizando o algoritmo de escalonamento Round Robin, com quantum de 4 unidades de tempo, teríamos o diagrama de tempo representado a seguir:
O tempo médio de espera é geralmente longo. O desempenho do algoritmo depende bastante da escolha do quantum. A troca de contexto (alternar entre um processo e outro) requer certa quantidade de tempo para ser realizada. Sendo assim, se o quantum definido for muito pequeno, ocasiona uma grande quantidade de trocas de processos e a efeciência da CPU é reduzida; de forma análoga, a definição do quantum muito grande pode tornar a política Round Robin numa FCFS comum.
Veja um exemplo:
Passo 1: O processo P1 é iniciado e executado durante o Quantum definido.
Passo 2: Como o Quantum é menor que o tempo necessário, após o decorrer do período definido, a execução será interrompida e o processo P1 retornará ao fim;
Passo 3: O processo P2 será executado;
Passo 4: O quantum definido é o suficiente para a execução total do processo, que passará para o estado terminado.
Escalonamento por múltiplas filas implementa diversas filas de processos no estado de pronto, uma para cada prioridade. Os processos devem ser classificados previamente em função do tipo de escalonamento para poderem ser corretamente alocados.
Cada fila separada tem seu próprio algoritmo de escalonamento. Exemplo: Fila de foreground (interativos) usa escalonamento Round Robin, enquanto os processos da fila de background (batch) utilizam algoritmo FCFS.
Prioridade: Processos do sistema -> Processos interativos -> Processos batch
Note
Note que a prioridade é da fila não do processo.
Escalonamento por múltiplas filas com realimentação: No caso de processos que alterem seu comportamento, no decorrer do tempo, o esquema anterior é falho, porque não permite a movimentação do processo entre as filas. Este escalonamento permite a troca entre as filas. O sistema tenta identificar dinamicamente o comportamento de cada processo, ajustando suas prioridades de execução e mecanismos de escalonamento. Este esquema é dito mecanismo adaptativo. Veja o exemplo:
Maior prioridade:
- Fila 1 (escalonamento FIFO), quantum = 8; Término do quantum.
- Fila 2 (escalonamento FIFO), quantum = 16;
- Fila N (escalonamento circular)
Menor prioridade:
Quando o processo é criado, é posto na fila 1 (de mais alta prioridade). Se ele esgota seu quantum, é posto uma fila abaixo e recebe um novo quantum (maior). Se também esgota esse quantum, vai descendo sucessivamente de fila, até atingir a de menor prioridade, onde o escalonamento é circular.
Neste esquema, os processos "I/O bound" ficam por mais tempo nas filas de alta prioridade, enquanto os "CPU bound" gastam seu tempo e passam para filas de menor prioridade. Ou seja, os processos evoluem bem, independentemente da sua natureza (I/O bound ou CPU bound).
Escalonamento com múltiplos processadores é usado quando existem vários processadores.
-
Compartilhamento de carga: Fornece uma fila separada para cada processador.
-
Problema: Um processador pode estar ocioso enquanto o outro está sobrecarregado.
-
Solução: Colocar uma só fila de prontos e deixar o escalonador decidir na hora da execução.
Existem 3 formas par este tipo de escalonamento:
-
Forma 1: Uma maneira de escalonar é o processador ser autoescalonável, ou seja, cada processador vai à fila e seleciona um processo. Cuidado a serem tomados:
- Não permitir que um processo seja escolhido por mais de um processador;
- Não permitir que um processo não seja escolhido por nenhum processador.
-
Forma 2: Outra maneira é usar um processador como escalonador de processos para os outros processadores, criando uma estrutura mestre-escravo (master-slave).
-
Forma 3: A terceira possibilidade é o multiprocessamento assimétrico, onde um processador é responsável por todas as decisões de escalonamento, processamento de E/S, etc. Os demais processadores só executam código do usuário. Para sistemas de tempo-real, é importante definir alguns conceitos críticos:
- Tempo de chaveamento: É aquele gasto pelo sistema para chavear o processamento entre dois processos independentes, ativos e de prioridade igual. Ocorre, por exemplo, no chaveamento por "time-slice".
- Tempo de preempção: É aquele que um processo de maior prioridade leva para tomar o controle de um, de menor prioridade, por ocasião da ocorrência de um determinado evento externo de interrupção.
- Tempo de latência de interrupção: É aquele entre o recebimento de um pedido de interrupção pelo CPU e a execução da primeira instrução da rotina de serviço da interrupção.
Escalonamento de tempo real podemos dividir o escalonamento de tempo real em dois tipos de sistemas. São eles:
- Sistemas de tempo real hard: Nestes sistemas, como as tarefas têm que terminar em tempos definidos, o SO tem que admitir o processo somente quando ele poderá terminar na hora certa; caso contrário, o SO deve rejeitar o pedido como impossível. Isto é conhecido como "Reserva de recurso". Para ter tempos garantidos, recursos tais como memória virtual e armazenamento em disco, estão descartados. Normalmente, este tipo de sistema possui hardware específico.
- Sistemas de tempo real soft: Neste tipo, os processos de tempo real devem ter a mais alta prioridade. Essa prioridade não deve ser degradada com o tempo. Para esses processos, não deve haver time sharing. O tempo de latência deve ser pequeno para que o processo possa começar a executar o mais rapidamente possível. Em todos os casos, o tempo de chaveamento e de latência devem ser pequenos, o tempo de preempção deve ser adequado aos propósitos do sistema e, em alguns casos, podem existir primitivos de bloqueio da preempção.
Como vimos anteriormente, o espaço de endereçamento lógico de um programa tem que ser mapeado em um espaço de endereçamento físico de memória. De fato, essa correspondência pode ser deixada totalmente a cargo do SO, de forma que o programa não tenha nenhuma responsabilidade em se ater a um determinado tamanho de memória física disponível.
Memória virtual é um mecanismo de armazenamento que oferece ao usuário a ilusão de ter uma memória principal muito grande. Isso é feito tratando uma parte da memória secundária como memória principal. Na memória virtual, o usuário pode armazenar processos com tamanho maior que a memória principal disponível.
Portanto, em vez de carregar um processo longo na memória principal, o sistema operacional carrega as diversas partes de mais de um processo na memória principal. A memória virtual é implementada principalmente com paginação e segmentação por demanda.
Assim, o conjunto de endereços que um programa pode endereçar, pode ser muito maior que a memória física disponível para o processo, em um determinado momento, ou mesmo que o total de memória fisicamente disponível na máquina. A esse conjunto de endereço, chamamos de espaço de endereçamento virtual. Ao conjunto de endereços reais de memória chamamos espaço de endereçamento real.
Como os programas podem ser maiores que a memória física, somente uma parte de cada programa pode estar na memória durante a execução. As partes que não são necessárias em um determinado instante, ficam em disco e só carregadas quando se tornarem necessárias. Todo o processo é transparente para o usuário e mesmo para os compiladores e link-editores, pois estes trabalham apenas com o espaço de endereçamento virtual. Apenas o SO se incube de carregar ou descarregar as partes necessárias e mapeá-las no espaço de endereçamento real durante a execução.
Como consequência desse mapeamento o programa não precisa estar nem mesmo em regiões contíguas de memória. Naturalmente, o nível de fracionamento do programa deve ser escolhido de forma a não comprometer o desempenho, à medida que a tarefa de mapeamento é feita pelo SO, juntamente com recursos de hardware. Assim, a memória (tanto virtual como real) é dividida em blocos e o SO mantém tabelas de mapeamento para cada processo, que relacionam os blocos da memória virtual do processo com os blocos da memória real da máquina.
Na Paginação, o espaço de endereços é dividido em blocos de igual tamanho que chamamos de páginas. A memória principal também é dividiada em blocos de mesmo tamanho (igual ao tamanho da página) denominamos molduras. Esses blocos de memória real são compartilhados pelos processos, de forma que a qualquer momento, um determinado processo terá algumas páginas residentes na memória principal (as páginas ativas), as restantes na memória secundária (as páginas inativas).
A paginação permite que o programa possa ser espalhado por áreas não contíguas de memória. Com isso, o espaço de endereçamento lógico de um processo é dividido em páginas lógicas de tamanho fixo e a memória física é dividida em páginas com tamanho fixo, com tamanho igual ao da página lógica. Nisso, o programa é carregado página a página, cada página lógica ocupa uma página física e as páginas físicas não são necessariamente contíguas.
O endereço lógico é inicialmente dividido em duas partes : um número de página lógica (usado como índice no acesso a tabela de páginas, de forma a obter o número da página física correspondente) e um deslocamento dentro da página. Não existe fragmentação externa, porém existe fragmentação interna (Ex: um programa que ocupe 201kb, o tamanho de página é de 4 kb, serão alocadas 51 páginas resultando uma fragmentação interna de 3kb). Além da localização a tabela de páginas armazena também o bit de validade, (1 ou TRUE) se a página está na memória (0 ou FALSE) se a página não está na memória. E a transferência das páginas de processo podem ser transferidas para a memória por demanda, levando apenas o que é necessário para a execução do programa ou por paginação antecipada, onde o sistema tenta prever as páginas que serão necessárias à execução do programa. Abaixo um exemplo de páginas constantemente referenciadas:
O mecanismo da paginação possui atribuições:
-
Executar a operação de mapeamento, isto é, determinar qual a página referenciada e em que bloco de memória (se for o caso) ela se encontra;
-
Transferir páginas da memória secundária para os blocos da memória principal (quando for requerido) e guarda-las de volta na memória secundária quando elas não estiverem em uso.
Com o objetivo de determinar qual a página referenciada por um endereço de programa, interpreta-se os bits mais significativos do endereço virtual como sendo o número da página dentro de uma tabela de páginas que é mantida pelo SO para cada processo ativo. Já os bits menos significativos indicam a localização da palavra na página selecionada:
Memória Virtual: Mapeamento de Endereços
Se o tamanho da página é 2n palavras, então, os n bits menos significativos do endereço de programa representam o deslocamento, e os bits restantes indicam o número da página. O número total de bits do endereço de programa é suficiente para endereçar inteiramente a memória virtual.
A divisão de um endereço de programa no par (número de página, deslocamento) é feita pelo hardware e é completamente transparente ao programador. Para transformar o par no endereço de uma posição de memória, o mecanismo conta com a tabela de páginas: p-ésima entrada da tabela, aponta para o bloco "q" da memória que contém a página de número "p". O número da palavra "d" é somado a "q", formando o endereço.
Com a tabela de páginas (q) e o bloco de memória (q-ésimo bloco), o mapeamento na paginação é:
f(a)= endereço de programaf(p,d)= deslocamento (número de palavras)q+d= endereço inicial do bloco associado à página p
Se chamarmos de Z o tamanho da página, então: "p" é quociente e "d" o resto da divisão de "a" por Z.
Vamos supor que tivéssemos:
- Páginas com 16 endereços, logo, 4 bits de endereçamento;
- Endereços virtuais de até 10 bits, logo, 1024 endereços;
- Memória física de 256 endereços;
Então, se quiséssemos acessar o endereço binário 001001011 a composição, pelo esquema acima, seria:
- Os quatro últimos bits (
0111) são o deslocamendoddentro da página. - Os seis primeiros bits (
001001) são o número da página.
Como temos 1024 endereços e páginas de 16 endereços, então temos 1024/16 = 64 páginas da tabela de páginas. Como temos 256 endereços reais, então temos 256/16 = 16 blocos físicos de memória (blocos de 0 a 15).
Page fault: Normalmente, o número de blocos alocados a um processo é menor do que o número de páginas que ele usa. Por isso, é possível que um endereço de programa referencie uma página ausente. Nesse caso, a entrada (da tabela) correspondente estará "vazia" e uma interrupção do tipo falta de página (page fault) é gerada sempre que uma página inativa é requerida. Observe:
A interrupção faz com que o mecanismo da páginação inicie a transferência da página ausente da memória secundária para um dos blocos da memória principal e atualize a tabela de páginas. O processo muda de estado, ficando bloqueado até que a transferência chegue ao fim.
As páginas são transferidas da memória secundária para a principal apenas quando são referenciadas. Esse mecanismo é chamado de paginação por demanda. Em outra técnica, conhecida como paginação antecipada, o sistema tenta prever quais páginas serão referenciadas pelo programa, trazendo-os para a memória antecipadamente, evitando assim a ocorrência do page fault.
A posição ocupada por uma página na memória secundária é guardada em uma tabela separada ou na própria tabela de páginas. No último caso, é necessário um "bit de presença" para cada entrada da tabela de páginas, indicando se a página está ativa (está na memória física) ou não.
Se não houver nenhum bloco de memória disponível então é necessário desocupar um dos blocos para a página cuja presença está sendo solicitada. A escolha do bloco é função do algoritmo de troca informações requeridas pelo algoritmo estão contidas na tabela de página e poderiam ser, por exemplo:
- Contador de acessos à página;
- Quando a página foi acessada pela última vez;
- Se a página foi alterada ou não.
A transformações de endereços é função do hardware, enquanto que o algoritmo de troca é feito pelo software.
As políticas de paginação para minimizar a ocorrência de page faults surgiu o conceito de working set. Define-se working set como o conjunto de páginas mais acessadas para um determinado processo: Assim, quando um programa começa a executar, a possibilidade de que ele requisite páginas que não estão na memória é muito grande. Entretanto, à medida que mais páginas vão sendo carregadas, a ocorrência de page faults vai diminuindo, devido ao princípio da localidade dos programas, já explicado quando falamos de memória cache.
Assim, cabe ao SO definir um conjunto de páginas que devem ficar carregadas, sabendo que se trata de um compromisso entre capacidade e velocidade.
-
Capacidade: Quanto mais páginas no workinhg set menos processos podem estar carregados ao mesmo tempo.
-
Velocidade: Quanto mais páginas no working set menos page fault ocorrem, logo, melhor desempenho.
Definindo o working set, resta definir qual deve ser a página a retirar da memória quando ocorre um page fault e uma página precisa ser carregada. Esta decisão pode obedecer a várias políticas, como veremos a seguir. Entretanto, antes de descartar qualquer página, o SO precisa saber se houve alguma alteração na página enquanto ela esteve na memória. Se houve, então ela precisa ser salva em disco antes de ser descartada, para que nenhum dado se perca. Para tanto, o SO mantém um bit na tabela de páginas chamada bits de modificação. Caso o bit indique que houve mudança, a página é salva em um arquivo de paginação, onde poderá ser futuramente resgatada.
As políticas de liberação de páginas são:
-
Página aleatória: escolhe-se simplesmente qualquer página. A desvantagem é que pode se escolher uma página que seja muito acessada.
-
FIFO - First-in-first-out: Retira-se a própria carregada há mais tempo. A desvantagem é que pode retirar páginas que são acessadas periodicamente.
-
Least-recently-used: Retira-se a página utilizada pela última vez há mais tempo. A desvantagem é o overhead causado pela necessidade a cada acesso de atualização do momento em que a página foi acessada.
-
Least-frequently-used: Escolhe-se a página que tenha o menor número de acessos descritos em um contador de acessos descritos em um contador de acessos. A ideia é manter, na memória, as páginas que são muito acessadas, entretanto, o problema é que páginas recém-carregadas no working set terão baixo número de acessos e serão indesejavelmente cotadas para serem retiradas.
-
Not-recently-used: A página não utilizada nos últimos k acessos é substituída. A desvantagem também é o overload causado pela necessidade, a cada acesso, de atualizar um contador de acessos à página.
Existem vantagens e desvantagens da paginação:
-
Vantagens: Aumenta o espaço de endereçamento do processo; Admite código reentrante e compartilhamento de código pelos processos.
-
Desvantagens: Overhead devido ao excesso de page faults tratados pelo sistema; Ocupa um arquivo só para E/S de páginas. Ocupa muita memória do SO para as tabelas de páginas dos processos.

Administração de memória por segmentação: Devido ao grande número de page faults da paginação, a segmentação surgiu como uma alternativa de gerência de memória onde o programa agora não mais é dividido em blocos de comprimentos fixos (as páginas), mais sim, em segmentos de comprimentos variados, mas com um sentido lógico, isto é, a paginação procedia a uma divisão física do programa e, às vezes, isso leva a um número muito grande de page faults por não observar suas características lógicas.
A segmentação busca aproveitar exatamente essas características, agrupando em um segmento partes do programa que se referenciam mutuamente e que quando trazidas à memória estarão todas juntas não causando, o que nesse caso é chamado de segment faults, com tanta frequência.
Nesse esquema, o espaço de endereços torna-se bidimensional: endereços de programas são denotados pelo par (nome do segmento, endereço dentro do segmento). Para facilitar a implementação do mecanismo de transformação de endereços, o SO troca o nome do segmento por um n°, quando o segmento é referenciado pela primeira vez.
Considerando o par (s,d) como sendo um endereço de programa generalizado, onde s = número do segmento e d = endereço dentro do segmento, então o esquema de geração seria:
Conforme podemos ver, a transformação de endereço é realizada por intermédio de uma tabela de segmentos (uma tabela para cada processo). A s-ésima de entrada da tabela contém o tamanho (1) e a posição inicial (a) da memória, onde o s-ésimo segmento foi carregado.
As entradas da tabela são chamadas de descritores de segmento. O algoritmo de mapeamento é:
- extrair endereço de programa
(s,d); - usar "s" para indexar tabela de segmentos;
- retirar o endereço inicial do segmento (a);
- se
d<0oud>1então "violação de memória"; a+dé o endereço requirido;
A busca de espaços para um segmento a ser trazido à memória nos leva novamente aos problemas de gerência por partições variáveis. A diferença aqui é que o espaço contíguo só é necessário para o segmento e não para todo o processo.
A segmentação possui algumas vantagens e desvantagens. São eles:
-
Vantagens: Reduz o número de page faults dentro de um segmento; Aproveita as características lógicas do processo; Dispensa uso de arquivo de paginação (ou segmentação).
-
Desvantagens: A soma de
s+d, na tradução de endereços, é mais lenta que a concatenaçãopedna paginação; A administração das áreas livres de memória é mais complicada (partições variáveis) e, portanto mais lenta; As page faults (tratadas mais rapidamente, pois as páginas eram menores) são substituídas por segment faults que são maiores em comprimento.
Sistemas que usam segmentação pura: B-6700 e PD-11/45.
Administração por segmentação com paginação: Na administração por segmentos, nem sempre é possível manter todos os segmentos na memória principal. Segmentos muito grandes poderiam, eventualmente, ultrapassar a memória disponível da máquina. Então, o que fazer?
Nesse caso, há duas saídas:
- Limitar o tamanho máximo de um segmento;
- Empregar a técnica da paginação na implementação da segmentação;
- Implementar segmentação via paginação, consiste em: Dividir o programa em segmentos; Dividir os segmentos em páginas.
Em tempo de execução, alguns trechos de um segmento estariam na memória principal e outros não. A entrada da tabela de segmentos, isto é, o descritor de um segmento, apontaria para uma tabela de páginas (do segmento) ou então estaria vazia.
Vantagens do uso de paginação na implementação da segmentação:
- Não é necessário manter todas as páginas de um segmento na memória - apenas aquelas usadas corretamente.
- As páginas de um segmento não precisam ser carregadas em áreas contíguas, isto é, podem ser dispersadas pela memória.

Os barramentos (ou buses) são linhas de comunicação entre a CPU, a PM e os I/O controllers. São vias físicas (geralmente representadas como linhas) que permitem a comunicação entre os principais componentes do sistema computacional, como:
- CPU (Unidade Central de Processamento): onde ocorre o processamento dos dados;
- PM (Memória Principal): onde os dados e instruções são armazenados temporariamente;
- Controladores de Entrada/Saída (I/O Controllers): que gerenciam os dispositivos periféricos como teclado, mouse, disco rígido, impressora, etc.
Esses barramentos podem ser de três tipos principais:
- Barramento de dados: carrega as informações (dados propriamente ditos) entre os dispositivos.
- Barramento de endereços: carrega os endereços de memória dos dados (ou periféricos) a serem acessados.
- Barramento de controle: carrega sinais de controle que coordenam as ações entre os dispositivos, como leitura, escrita, interrupções etc.

Portanto, os barramentos são essenciais para que os componentes de um computador troquem informações de forma sincronizada e eficiente. Eles são como as estradas por onde o tráfego digital circula dentro da máquina.
De acordo com a transmissão, podem ser unidirecionais (um só sentido) ou bidirecionais (em dois sentidos).
Exemplo: Comunicação CPU/MM
-
Barramento de Dados: Transmite informações entre as unidades funcionais (MBR).
-
Barramento de Endereços: Especifica o endereço da célula a ser acessada (MAR).
-
Barramento de Controle: Sinais relativos a leitura/gravação.


Os Registradores (CPU Registers) são dispositivos de alta velocidade localizados na CPU, onde armazenam dados temporariamente. Alguns são de uso específico, outros de uso geral. O número varia de acordo com a arquitetura do processador, Merecem destaque:
-
Contador de instruções (program counter - PC): armazena a instrução que a CPU deve executa.
-
Apontador da pilha (stack pointer - SP): contém o endereço da memória do topo da pilha (estrutura do sistema que guarda informações sobre tarefas que tiveram de ser interrompidas por algum motivo).
-
Registrador de estado (program status word - PSW): armazena informações sobre a execução do programa, como overflow.
Um buffer overflow (transbordamento de dados) acontece quando um programa informático excede o uso de memória assignado a ele pelo sistema operacional, passando a escrever no setor de memória contíguo.
Bibliografia:
- https://pt.wikiversity.org/wiki/Introdu%C3%A7%C3%A3o_aos_Sistemas_Operacionais/Ger%C3%AAncia_de_Dispositivos Como cada componente computacional funciona? Veremos mais sobre as arquiteturas computacionais e os tiṕos de componentes envolvidos!

O clock é um dispositivo da CPU que gera pulsos elétricos constantes (síncronos) em um mesmo intervalo de tempo (sinal de clock).
Este intervalo determina a frequência de geração dos pulsos e consequentemente seu período. A cada período do sinal de clock dá-se o nome de estado. O sinal é usado pela CU para executar as instruções.
Como uma instrução demora vários estados, em um estado apenas parte dela é executada. O tempo de duração da instrução é determinado pelo seu número de estados e o tempo de duração do estado.
Arquiteturas de microprocessadores comumente usam dois métodos diferentes para armazenar os bytes individuais na memória. Essa diferença é chamada de "ordenação de bytes" ou "natureza endian".
-
Processadores Intel x86 Little Endian: armazenam um inteiro de dois bytes, com o byte menos significativo primeiro, seguido pelo byte mais significativo. Isso é chamado de ordenação de bytes little-endian.
-
Big Endian: Na ordem de bytes big endian, o byte mais significativo é armazenado no endereço de memória mais baixo, e o byte menos significativo é armazenado no endereço de memória mais alto. Arquiteturas mais antigas PowerPC e Motorola 68k frequentemente usam big endian. Em comunicações de rede e armazenamento de arquivos, também usamos big endian. A ordenação de bytes torna-se significativa quando dados são transferidos entre sistemas ou processados por sistemas com endianness diferente. É importante lidar corretamente com a ordem dos bytes para interpretar os dados de forma consistente entre diversos sistemas.
Em computação, a memória (memory) refere-se ao hardware que armazena dados e instruções para uso imediato pelo computador. É essencial para a operação do computador, permitindo que o processador acesse rapidamente as informações necessárias para executar tarefas. A memória é dividida em dois tipos principais: memória principal (ou primária) e memória secundária.
Hierarquia de memória:
A memória principal (IM/MM/PM - Internal/Main/Primary Memory), também chamada de memória primária, é o local onde o computador guarda as informações e as instruções que estão sendo utilizadas no momento. É como a memória de trabalho da CPU, onde os dados e programas são armazenados temporariamente para que possam ser acessados rapidamente durante o processamento. Composta por unidades chamadas células e volátil (necessita estar energizada), o tamanho da célula (em bits) varia de acordo com a arquitetura do equipamento e o acesso é feito através de um número chamado endereço de memória.
O endereço é especificado no registrador de endereço de memória (Memory Register Address - MAR). Com o conteúdo desse registrador a CPU acessa o endereço. O conteúdo do endereço acessado é armazenado no registrador de dados de memória (memory buffer register - MBR).
Aqui está uma explicação simples que mostra como os dados se movem pelo sistema, desde a entrada até o processamento e o armazenamento.
- Os dados entram por fontes de entrada como teclado, mouse, câmera ou sistemas remotos.
- O armazenamento permanente guarda seus arquivos, aplicativos e mídias do sistema. Isso inclui discos rígidos, drives USB, ROM/BIOS e armazenamento baseado em rede.
- A RAM é o espaço de trabalho do seu computador. Inclui memória física e memória virtual, que armazenam temporariamente dados e programas enquanto você os usa.
- A memória cache fica mais próxima da CPU e é dividida em Nível 1 e Nível 2. Ele ajuda a acelerar o acesso aos dados frequentemente usados.
- Registradores de CPU são as unidades de memória mais rápidas e menores. Eles são usados diretamente pelo processador para executar instruções quase instantaneamente.
Quanto mais alto você sobe na pirâmide de memória, mais rápido e menor será o armazenamento.
Ao compreender os papéis e capacidades de cada tipo de memória, desenvolvedores e arquitetos de sistemas podem projetar sistemas que aproveitem efetivamente as forças de cada camada de armazenamento, levando a uma melhoria no desempenho geral do sistema e na experiência do usuário.
Alguns dos tipos comuns de memória são: Os tipos de memória variam em velocidade, tamanho e função, criando uma arquitetura multicamadas que equilibra custo com a necessidade de acesso rápido aos dados.
-
Registradores: Armazenamento minúsculo e ultrarrápido dentro da CPU para acesso imediato aos dados.
-
Caches: Memória pequena e rápida localizada próxima à CPU para acelerar a recuperação de dados.
-
Memória Principal (RAM): Armazenamento primário maior para programas e dados em execução atualmente.
-
Drives de Estado Sólido (SSDs): Armazenamento rápido e confiável, sem partes móveis, usado para dados persistentes.
-
Discos rígidos (HDDs): Discos mecânicos com grande capacidade para armazenamento de longo prazo.
-
Armazenamento Secundário Remoto: Armazenamento externo para backup e arquivamento de dados, acessível via rede.
A memória de acesso randômico ou de acesso aleatório (do inglês Random Access Memory, conhecido pela abreviatura RAM), também chamado de memória volátil de leitura e escrita, é uma memória temporária computacional de acesso rápido; ou seja, é um local de armazenamento temporário de informações digitais usada pelo processador para armazenar informações temporariamente e que possui um acesso feito de forma aleatória mais rápido que ao HD, DVD, pendrive (permite a rápida leitura e escrita de informações), utilizada como memória primária em sistemas eletrônicos digitais. O termo acesso aleatório permite acessar qualquer informação armazenada em qualquer momento.
Memória para um dispositivo eletrônico digital com base em R/W - Read/ Write (Leitura/ Escrita).
A RAM é um componente essencial vários tipos de dispositivos, como: computador pessoal, computador servidor, smartphone, pois é onde basicamente ficam armazenados os programas básicos operacionais. Por mais que exista espaço de armazenamento disponível, na forma de um HDD, SSD ou memória flash, é sempre necessária uma certa quantidade de RAM.
O termo acesso aleatório identifica a capacidade de se ter acesso a qualquer posição e em qualquer momento, por oposição ao acesso sequencial imposto por alguns dispositivos de armazenamento, como fitas magnéticas. O nome não é verdadeiramente apropriado, já que outros tipos de memória (como a ROM) também permitem o acesso aleatório a seu conteúdo. O nome mais apropriado seria: Memória de Leitura e Escrita, que está expressa na programação computacional.
Apesar do conceito de memória operacional de acesso aleatório ser bastante amplo, atualmente o termo é usado apenas para definir um dispositivo eletrônico que o implementa, uma vez que atualmente essa memória se encontra espalhada dentro do próprio sistema dos atuais computadores (sistema por assim dizer "nervoso" do computador, como o humano), basicamente um tipo específico de chip. Nesse caso, também fica implícito que é uma memória volátil, todo o seu conteúdo é perdido quando a alimentação da memória é desligada. A memória principal de um computador baseado na Arquitetura de Von-Neumann é constituída por RAM. É nesta memória que são carregados os programas em execução e os respectivos dados do utilizador. Uma vez que se trata de memória volátil, os seus dados são perdidos quando o computador é desligado. Para evitar perdas de dados, é necessário salvar a informação para suporte não volátil, como o disco rígido.
É usada pelo processador para armazenar os arquivos e programas que estão sendo processados. A quantidade de RAM disponível tem um grande efeito sobre o desempenho, já que sem uma quantidade suficiente dela o sistema passa a usar memória virtual, que é lenta. A principal característica da RAM é que ela é volátil, ou seja, os dados se perdem ao reiniciar o computador. Ao ligar é necessário refazer todo o processo de carregamento, em que o sistema operacional e aplicativos usados são transferidos do HD para a memória, onde podem ser executados pelo processador.
Os chips de memória são vendidos na forma de pentes de memória. Existem pentes de várias capacidades, e normalmente as placas possuem dois ou três encaixes disponíveis. Há como instalar um pente de 1 GB junto com o de 512 MB que veio no micro para ter um total de 1 536 MB, por exemplo.
Tipos de Memória RAM:
-
SRAM (Static RAM) Não precisa ser atualizada constantemente: Mantém os dados armazenados sem a necessidade de atualização. Custo alto: É mais caro do que a DRAM.
-
DRAM (Dynamic RAM) Precisa ser atualizada constantemente: Para manter os dados armazenados. Custo baixo: É o tipo mais comum e barato de RAM.
- SDRAM (Synchronous DRAM) Sincronizada com o clock do processador: Melhora o desempenho e a eficiência. Taxa de transferência alta: É mais rápida do que a DRAM convencional.
- DDR SDRAM (Double Data Rate SDRAM) Transferência de dados em ambos os ciclos de clock: Dobra a taxa de transferência de dados. Versões: DDR, DDR2, DDR3, DDR4 e DDR5.
- RDRAM (Rambus DRAM) Arquitetura de barramento: Permite taxas de transferência mais altas. Custo alto: É mais caro do que a SDRAM.
- FB-DIMM (Fully Buffered DIMM) Buffer de memória: Melhora a estabilidade e a confiabilidade. Taxa de transferência alta: É mais rápida do que a DDR2.
Modelos de Memória RAM:
- DDR3:
- DDR4:
- DDR5:
As memórias ROM - Read Only Memory (Memória de Somente Leitura) são memórias somente de leitura, ou seja, é um tipo de memória que permite apenas a leitura, ou seja, as suas informações são gravadas pelo fabricante uma única vez e após isso não podem ser alteradas ou apagadas, somente acessadas. São memórias cujo conteúdo é gravado permanentemente.
Uma memória somente de leitura propriamente dita vem com seu conteúdo gravado durante a fabricação. Atualmente, o termo Memória ROM é usado informalmente para indicar uma gama de tipos de memória que são usadas apenas para a leitura na operação principal de dispositivos eletrônicos digitais, mas possivelmente podem ser escritas por meio de mecanismos especiais. Entre esses tipos encontramos as PROM, as EPROM, as EEPROM e as memórias flash. Ainda de forma mais ampla, e de certa forma imprópria, dispositivos de memória terciária, como CD-ROMs, DVD-ROMs, etc., também são algumas vezes citados como memória ROM.
Tipos de memória ROM:

-
Mask-ROM, também conhecida como programada por máscara ou MROM, tem seu conteúdo programado durante a fabricação do circuito integrado. Ela recebe este nome porque partes do clip são feitas com fotomáscaras, usadas durante o processo de fotolitografia.
-
PROM - Programmable Read-Only Memory, ou "memória somente de leitura programável". Ela sai de fábrica vazia, sendo programada por terceiros por meio de programador PROM. Estes dispositivos usam altas tensões para destruir partes do chip ou criar links internos nos circuitos. Por essa razão, a PROM só pode ser programada uma vez e não pode ser alterada.
-
EPROM - Erasable Programmable Read-Only Memory, "memória somente de leitura programável apagável", caracteriza-se por conseguir ser apagada. Para isso, no entanto, é necessária expô-la a uma forte luz ultravioleta. A regravação após este procedimento requer uma tensão ainda maior do que nas vezes anteriores, causando desgaste após um ciclo de aproximadamente mil reescritas.
-
EEPROM - Electrically Erasable Programmable Read-Only Memory, que em português significa "Memória Somente de Leitura Programável Apagável Eletricamente". É uma espécie de versão mais moderna da EPROM, que pode ser apagada e reescrita via eletrecidade, e não por luz ultravioleta. Uma das vantagens deste método é que a EEPROM não precisa ser retirado do circuito para ser limpa ou reprogramada.
A diferença entre RAM e ROM são:
RAM (Memória de Acesso Aleatório):
- Volátil: Perde os dados quando o computador é desligado.
- Temporária: Armazena dados e programas apenas enquanto o computador está ligado.
- Rápida: Permite acesso rápido aos dados.
- Escrita e leitura: Permite que os dados sejam escritos e lidos.
ROM (Memória Somente de Leitura):
- Não volátil: Mantém os dados mesmo quando o computador é desligado.
- Permanente: Armazena dados e programas permanentemente.
- Lenta: É mais lenta do que a RAM.
- Somente leitura: Permite apenas a leitura dos dados, não permitindo que sejam alterados.
No mundo da computação, um dump (do inglês "despejo") é uma cópia exata dos dados de uma memória (RAM, ROM, disco, etc.), exportada para um arquivo.
No caso de emuladores, um dump é a cópia dos dados da ROM (Read-Only Memory) de um cartucho, CD, DVD ou outro meio de armazenamento de um console. Emuladores (como PCSX2, Dolphin, RetroArch, etc.) tentam imitar o hardware de um console (PS2, SNES, Game Boy, etc.) em um computador.
Mas para funcionar, eles precisam dos jogos em formato digital, e não nos cartuchos ou discos físicos. Portanto, é uma Imagem ROM (Read Only Memory, em português "Memória Apenas Para Leitura") é uma cópia em arquivo do chip de memória ROM de um cartucho de video-game; ou a cópia do firmware de um sistema embarcado ou da máquina de arcade; ou a cópia ISO do CD/DVD do jogo eletrônico.
O termo ROM foi incialmente utilizado para outros tipos de memória não voláteis tais como PROM, EPROM, EEPROM e, memória-flash. Muitas vezes, é utilizado incorretamente para imagens de CD/DVD (imagem de disco) e de fita cassete (imagem de fita). ROMs ou jogos para emuladores e consoles são softwares como quaisquer outros. Portanto, seu uso indevido está sujeito aos rigores da lei.
Esses jogos são obtidos por meio de dumps. Ou seja:
| Termo | Significado no contexto de emuladores |
|---|---|
| ROM Dump | Cópia dos dados de um cartucho (ex: SNES, Game Boy, N64) |
| ISO Dump | Cópia dos dados de um CD/DVD de console (ex: PS1, PS2, Wii) |
| BIOS Dump | Cópia da BIOS do console (às vezes exigido pelo emulador) |
📁 Exemplos:
| Console | Tipo de Dump | Formato comum de arquivo |
|---|---|---|
| SNES | ROM | .sfc, .smc |
| Game Boy | ROM | .gb, .gbc, .gba |
| PlayStation 2 | ISO | .iso, .bin/.cue, .chd |
| Wii | ISO/WBFS | .iso, .wbfs |
| Nintendo Switch | NSP/XCI | .nsp, .xci |
🔧 Como os dumps são usados?
- Extração: Usa-se um dispositivo especial ou software no console original para extrair a ROM ou ISO (fazer o dump).
- Emulação: O emulador carrega esse arquivo como se fosse o cartucho ou disco original.
- Execução: O jogo roda como se estivesse no console, mas via software no PC ou celular.
- Fazer dump do seu próprio jogo é legal em muitos países, pois você está fazendo uma cópia de segurança.
- Baixar dumps de jogos que você não possui pode ser ilegal, mesmo que apenas para uso pessoal.
- Alguns emuladores exigem BIOS dump do console real — e distribuí-la sem licença também é ilegal.
Em fóruns de eletrônica, segurança e engenharia reversa, "MigDumper" pode se referir a uma ferramenta usada para fazer dump da memória MIG (MediaTek Internal Generator ou blocos de memória específicos) de celulares, tablets ou firmwares com chips MediaTek. Essas ferramentas são usadas geralmente para:
- Recuperar firmware
- Fazer backup de ROM
- Realizar engenharia reversa
- Analisar arquivos binários internos do dispositivo
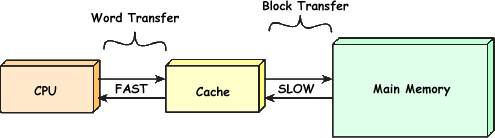
Memória cache (
- Alta velocidade;
- Antes de acessar um dado na MP o processador busca ele na memória cache;
- Se encontra, não acessa a MP; caso contrário transfere um bloco de dados a partir do dado referenciado para a cache;
- Maior performance;
- Maior custo.

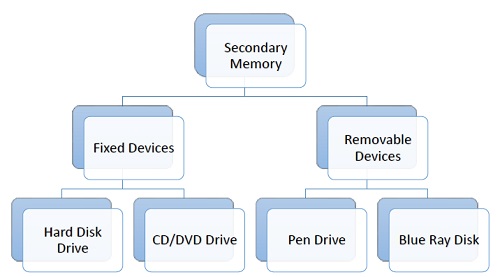
Memória Secundária
- Meio permanente de armazenamento (não-volátil);
- Acesso lento se comparado às outras memórias;
- Custo baixo;
- Capacidade de armazenamento muito superior à MP;
- Fitas magnéticas;
- Discos magnéticos e óticos.
Com a evolução da memória secundária, hoje temos SSDs e armazenamento em nuvem em ambientes SaaS.
A memória Flash difere das EEPROMs comuns que apagam a sua memória reescrevendo conteúdo ao mesmo tempo, o que os torna mais lentas para utilizar. A memória Flash pode apagar os dados em blocos inteiros, tornando-se a tecnologia preferida para aplicações que requerem uma atualização frequente de grande quantidade de dados, como no caso de um cartão de memória para um dispositivo eletrônico digital. FAT32 ou NTFS
A Gerência de Memória tornou-se um elemento importante nos sistemas de computação devido ao alto custo e a exiguidade desse recurso. Por outro lado, a necessidade de alocação de mais de um processo, na memória, nas propostas de sistemas que operam em multitarefa, tornam indispensável a existência deste gerenciamento.
Segundo a arquitetura de Von Neumann, programas e dados devem estar alocados em momória principal quando em execução, para que possam ser diretamente referenciados (acessados). O imperativo de gerenciar os espaços de memória decorre então da necessidade do sistema em saber onde estão localizadas as áreas de instruções e de dados dos processos que em execução.
Duas grandes abordagens da gerência de memória:
- Manter os processos na memória principal durante toda a sua execução;
- Mover os processos entre a MP e a MS (tipicamente disco), utilizando as técnicas de swapping (permuta) ou de paginação.
Gerenciamento sem permuta (alocação contígua) os primeiros sistemas implementaram uma técnica muito simples onde a memória principal disponível é dividida entre o Sistema Operacional e o programa em execução.
Como este esquema de gerenciamento é utilizado em sistemas monoprogramáveis, temos apenas um processo em execução por vez. Nesta técnica, o tamanho máximo dos programas é limitado à memória principal disponível. Para superar esta limitação foi desenvolvido o conceito de overlay que utiliza o conceito de sobreposição, ou seja, a mesma região da memória será ocupada por módulos diferentes do processo.
Neste caso, um programa que exceda o tamanho de memória disponível para o usuário, é particionado em segmentos de código de overlay que permanecem no disco até que sejam necessários, quando então são trazidos para memória e alocados a um espaço predeterminado pelo usuário quando da construção do módulo executável.
Esse gerenciamento é de responsabilidade do usuário e, geralmente, é oferecido como um recurso da linguagem. A técnica de overlay foi o primeiro uso do conceito de mover partes do processo, entre o disco e a memória principal que acabaria por gerar as modernas técnicas de gerenciamento de memória onde a divisão dos módulos é totalmente transparente para o usuário.
Em um programa com estrutura de overlay, um módulo fica sempre residente (Módulo Raiz) e os demais são estruturados como se fossem em uma árvore hierárquica de módulos mutuamente exclusivos, em relação a sua execução, colocados lado a lado, em um mesmo nível da árvore, de modo que o mesmo espaço possa ser alocado para mais de um módulo, os quais permanecem no disco e serão executados um de cada vez por meio de comandos de chamado (calls).
Um módulo residente faz chamadas a um módulo de overlay em disco e este é carregado no espaço de overlay sobre outro módulo do mesmo nível que estava lá (daí a necessidade de serem mutuamente exclusivos).
Veja o exemplo ao lado: Consideramos um processo composto por 3 módulos, o principal e os módulos 1 e 2.
-
Passo 1: Inicialmente o módulo principal é alocado na memória e o restante da área de usuários constitui a área de overlay;
-
Passo 2: Durante sua execução o módulo principal necessita de uma função do módulo 1, para poder acessá-la, o módulo é carregado na área de overlay.
-
Passo 3: Continuando a execução, o módulo principal referencia o módulo 2 que é carregado na área de overlay, sobrescrevendo o módulo 1. Devemos notar que somente os módulos pode estar na área de overlay a cada momento.
Alocação particionada fixa como o advento dos sistemas multitarefa surgiu, a necessidade de mais de um processo de usuário, na memória, ao mesmo tempo. A forma mais simples de se conseguir isso consiste em dividir a memória em n participações (possivelmente diferentes) e alocar os diferentes processos em cada uma delas.
Nos primeiros sistemas, estas participações eram estabelecidas na configuração do sistema operacional e seu tamanho e sua localização somente podiam ser alterados realizando um novo boot.
Quando um processo inicia, este deve ser alocado em uma participação com tamanho suficiente para acomoda-lo. Duas estratégias podem ser adotadas para alocar o processo: Uma única fila de entrada ou uma fila por participação. Observe um exemplo de cada estratégia: Fila de Entrada separadas por Participação x Fila única de Entrada por Participação.
Caution
Este método de gerência de memória baseado em participações fixas, se ele não ocupa todo o seu espaço, o restante não poderá ser utilizado por nenhum outro processo. Para evitar esse desperdício, foi desenvolvido um esquema de gerenciamento e alocação de memória dinamicamente, dependendo da necessidade do processo. Este esquema é conhecido como alocação com participações variáveis.
Alocação com participações variáveis, nessa técnica, a memória principal não é particionada em blocos de tamanhos predeterminados, tal como na participação fixa. Aqui, inicialmente, apenas uma participação existe e ocupa toda a memória disponível para usuários. À medida que os processos vão sendo alocados, essa partição vai diminuindo até que não caibam mais processos no espaço restante, resultando em um único fragmento.
Quando um processo termina e deixa a memória, o espaço ocupado por ele se torna uma participação livre que o gerente de memória utilizará para alocar outro processo da fila por memória. Uma lista por memória, uma lista de participações livres é mantida com ponteiros indicando os buracos disponíveis para alocação.
Exemplo:
- O processo A ao chegar, é carregado na memória e o seu tamanho define do tamanho da sua participação;
- Os processos B e C, de forma análoga, são carregados no espaçõ livre, ainda disponível;
- Ao chegar o processo D, não existe espaço livre contínuo suficiente para ele ser carregado. Ele deve então esperar que um espaço contíguo, de tamanho suficiente, esteja liberado.
- O processo A termina e então o processo D pode ser alocado. Note que, após alocar e desalocar vários processos, a memória pode se particionar.
A escolha da partição para o próximo job da fila deverá ser feita de acordo com uma das seguintes políticas (Partition Selection Algorithms):
-
First Fit: Aloca a primeira região capaz de conter o programa (busca termina assim que a primeira região é encontrada). É a mais rápida, produz no exemplo uma região resto de 80k. Probabilisticamente agrupa os jobs pequenos separando-os dos grandes.
-
Best Fit: Aloca a menor região capaz de conter o programa (a lista de áreas livres de memória tem que ser totalmente pesquisa). Produz nosso exemplo, menor "região resto", no caso 10k. Busca deixar fragmentos livres menores.
-
Worst Fit: Aloca a região livre disponível (a lista de áreas livres na memória tem que ser totalmente pesquisa). Produz a maior "região resto", no caso 130k, é a pior das três. Para nosso exemplo, consideramos um Processo C de 70k. Intuitivamente sempre caberá mais um job pequeno no espaço resultante.
As políticas de alocação de partição introduzem dois problemas essenciais que devem ser resolvidos: realocação e proteção. Vamos entender esses problemas, um processo, quando alocado na memória principal faz referências a posição da memória, ou seja, a endereços já estão associados à posições físicas do espaço de memória onde ele será alocado, diz-se que esse módulo está em Imagem de Memória, ou que ele está com Endereçamento Absoluto.
Para que um processo possa ser alocado, em qualquer posição da memória, ele não pode estar com endereçamento absoluto e, nesse caso, um mapeamento de endereços deverá ser feito entre os endereços dos objetos referenciados pelo processo (endereços lógicos) e os endereços absolutos (físicos) no espaço que eles estarão ocupando na memória principal.
Supondo "N" o espaço de endereços lógicos e "M" o espaço de endereços físicos, então o mapeamento de endereços pode ser denotado por uma função do tipo: f:N -> M
Mas, o que é a relocação de memória? É a função que mapeia os endereços lógicos em endereços físicos. Quando ela é feita pelo link editor, durante a resolução das referências em aberto, na geração do módulo de carga, os endereços são resolvidos em relação a uma base inicial e o processo só poderá ser alocado a partir dessa base, ou seja, sempre rodará no mesmo lugar da memória.
Alguns sistemas deixam essa tarefa de relocação para o carregador (loader) ou ligado-carregador (liker-loader) que faz a resolução das referências externas e a relocação de endereços no instante de carregador o processo na memória para sua execução.
Note que no primeiro caso (link-editor), a carga em imagem de memória sempre roda no mesmo lugar da memória, enquanto que, no segundo caso, pode rodar em qualquer lugar. Assim, a relocação poderá ser:
-
Estática: Quando o mapeamento de endereços é feito antes do carregamento do módulo, a realocação é dita estática.
-
Dinâmica: Para que a tradução dinâmica de endereços possa ser efetuada, é preciso que toda referência seja lógica, isto é, nenhum endereço no programa poderá estar representando uma posição física, pois será mapeado pelo hardware. Esse processo é chamado de Relocação dinâmica de endereços.
O registrador de relocação contém o endereço inicial de carregamento, a instrução em código de máquina contém o código da instrução e o endereço desejado.
Registradores Base e Limite: Quando um processo é carregado na memória, o endereço "inicial" é colocado em um registrador base e todos os endereços de programa são interpretados como sendo relativos ao endereço contido no registrador base. O mecanismo de transformação, neste caso, consiste em adicionar ao endereço do programa o endereço base, o que produz a localização da palavra de memória correspondente. Isto é:
B= endereço basea= endereço do programa
Consegue-se relocação dinâmica facilmente: basta mover o programa e corrigir o conteúdo do registrador base. Proteção pode ser obtida com a inclusão de um segundo registrador (registrador limite) contendo o endereço da última posição de memória que o processo pode acessar. O mapeamento de endereço realizado pelo mecanismo por "hardware" ou transformação é assim:
if a < 0 then VIOLACAO_DE_MEMORIA
a':=B+a {a' é a posição requerida}
if a' > limite then VIOLACAO_DE_MEMORIAO espaço de endereço mapeado é linear, seu tamanho é a diferença entre o registrador limite e o base. Esse tamanho é necessariamente menor ou igual do que o espaço de memória disponível na configuração de máquina.
Warning
Para reduzir o tempo de mapeamento, é conveniente que os registradores de base e limite sejam de processo rápido. O cursto dos registradores pode ser reduzido e a velocidade aumentada se os bits menos significativos desses registradores forem removidos. Se tal ocorrer, então o espaço de endereços deve ser múltiplo de 2n, onde n é igual ao número de bits removidos.
Gerenciamento de permuta: Alguns conceitos como:
Swap de memória denominamos swapping a política de remover um processo da memória toda vez que ele fica bloqueado. Assim que sua condição estiver satisfeita e ele retornar à fila de prontos, ele é, novamente carregado na memória.
Exemplo: Processo esperando por uma partição e que não consegue rodar porque não há uma participação grande o suficiente.
Um SO tem por finalidade permitir que os usuários do computador executem aplicações, com editores de texto, jogos, reprodutores de mídia (audio e vídeo), etc.

Uma unidade de processamento gráfico (GPU) é um circuito eletrônico especializado projetado para processamento de imagens digitais e para acelerar gráficos de computador, podendo estar presente como uma pl